
阿里云第一届PolarDB数据库性能大赛Java排名第一分享
参加天池大赛-阿里云第一届PolarDB数据库性能大赛,比赛以NVME Optane SSD为背景,在此之上开发单机存储引擎比拼性能,支持C++和Java语言。我的完赛成绩是Java语言排名第一,总排名20(共1653人参赛,队伍名称:neoremind),与C++第一差距在2.1%(<9s)。众所周知,类似的系统如果想榨干硬件,那么越贴近底层越好,Java存在一些天然的劣势,但是作为这么多年的资深JAVAer,还是想挑战一把。
1. 赛题介绍
2. 实现前的思考和最终成绩
413.69s(Write 116s + Read 103s + Range 193s) Write throughput:2.21G/s,Read throughput:2.49G/s,Range throughput:2.65G/s |
422.31s(Write 116s + Read 109s + Range 196s) Write throughput:2.21G/s,Read throughput:2.35G/s,Range throughput:2.61G/s |
3. 存储设计
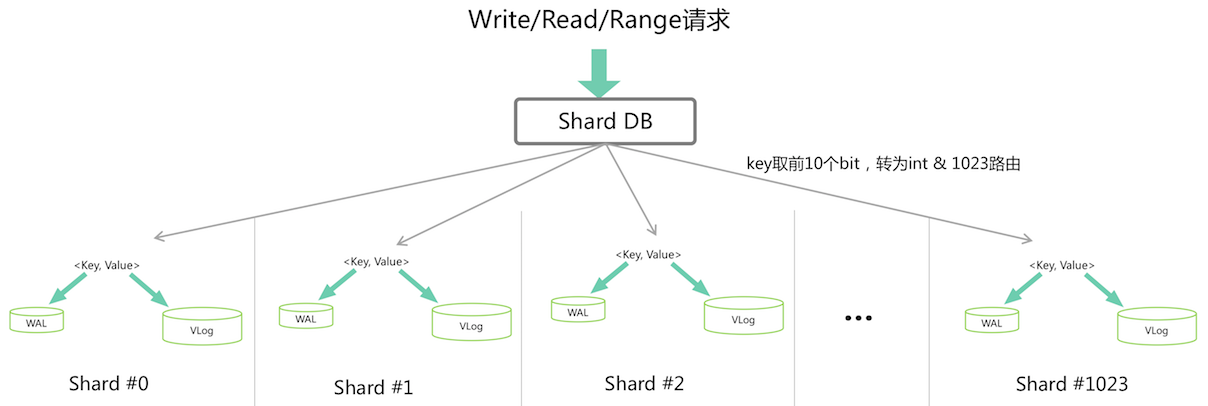
不采用LSM-tree模型,利用WisckKey论文的思想,做key、value分离。如下图所示。

wal(Write Ahead Log)存key和value在vlog中的offset,vlog是顺序写入的value,wal和vlog都是append-only的定长写入,所以wal只用存vlog的sequence,vlog seq用4byte Int表示存储,大尾端/小尾端程序自己定,然后乘以4096就是在vlog文件中的偏移量。关于vlog的gc问题题目不要求删除故不考虑。
wal和vlog都是顺序IO写入,不存在LSM-tree模型的写放大问题。
由于kv分离,写入必须lock,有锁就会限制性能,由于是随机写入,所以按照分治的思路,减少冲突即可,数据要分片sharding。我的策略是按照key的字典序分成1024个分片。把key的第一个字节8byte+第二个字节的前2个bit取出,转成int,经过分区函数就可以路由到正确的分片上。
4. 实现分析-Write
1024分片,单分片加锁写,流程如下
synchronized(lock) { write vlog 4k; write wal 8byte + 4byte vlog seq; vlog seq++; } |
可选择的IO方式有buffer io和direct io,而buffer io又可以考虑vfs read/write和mmap两种方式。
wal采用mmap方式写入,好处在于,第一,减少了一次内存拷贝,Java的FileChannel写入会经过byte[]->offheap direct memory->kernel page cache->disk的通路,而mmap则直接byte[]->内存映射地址(也算page cache)->disk,mmap直接是把文件映射到user space可访问的内存,读写都直接操作内存,不write through disk,仅需要一次mmap系统调用即可,close db的时候truncate掉后面的无用bytes;第二,crash consistency的保证,由于题目仅进行kill -9,不进行掉电,利用Page Cache,不同步刷盘保证数据一致性,而第二次启动由于vlog seq都是递增的,所以读wal遇到0x00000000,则可以丢弃后面的数据。
总的wal文件大小=(8byte key+4byte vlog seq)*64并发*100w=768MB。由于评测程序足够随机,每个wal大小=768MB/1024=750KB,所以每个分片可以直接通过mmap,映射为12byte<<16大小的文件,通过ensure capacity来做re-mmap,这样可以兼容正确性测试中的文件大小不平均,正确性程序的写入集中在5个分片中。
单个vlog文件大小=4k*6400w/1024=256MB。
vlog如果采用Java的FileChannel的,则相比C++多一次从heap到offheap direct memory的拷贝,走Page Cache后续echo 3 >/proc/sys/vm/drop_caches也算时间,故采用direct io。由于JDK并不提供direct io的API,可选择的有直接用JNA类库,通过JNI方式调用,或者采用封装了JNA的jaydio。我这里直接用了JNA的API。
顺序IO的问题解决了,那么上大块IO才能真正打满带宽,采用direct io的同时为了保证crash consistency,需要有个mmap在前面顶着,这里采用攒齐4个value,即16k value再写盘的策略,不断的擦写mmap同一块内存区域,正常关闭则删除掉mmap的临时文件,否则下次初始化的时候需要append这个mmap的文件内容到wal做recover。
全程young gc 4次,无full gc。Write on-CPU火焰图,86% IO + 4% 锁消耗 + 其他。基本达到目标。
.png)
5. 实现分析-Read
初始化数据库,在上面的写入分析中已经说明了部分,wal和vlog都需要做一些工作保证crash consistency。下一步就是如何建立索引,支持point lookup。
分析来看,总的wal文件大小768MB,索引完全可以放到内存,每个分片建索引流程如下:
1)load wal形成key 8byte + vlog seq 4byte
2)排序这12个byte,先按照key字典序排序,再按照vlog seq取最大的,来应对duplicate key情况。
3)把排序好的数据放到内存中。
这个过程每个分片是独立的,可以并行化。这个环节是Java做的不够好的地方,64并发load共耗时1.5-2.5s,有抖动,而且不及C++的300ms,慢了不少。排序的话采用字节一个个比较,或者把key转成unsigned long再比较差距不大,分析来看应该是由于cache line的原因。由于后一个阶段还需要Range,为了避免这个过程再重复,所以可以选择性的把已排序、去重好的key+vlog seq持久化到磁盘,做一个wal.sort文件。
由于key 8byte + vlog seq 4byte定长,所以在内存里用二分查找即可。我的实现采用了offheap内存,通过JDK的Unsafe来malloc和free内存,避免放到heap中的old region,存在GC overhead。内存二分查找开销非常低,占总耗时1%左右。
一次point lookup需要一次内存二分查找+一次磁盘IO。从磁盘读4k value只需要把vlog seq * 4096还原成实际的文件offset即可,通过offset从vlog读4k数据,也需要考虑buffer io还是direct io,在集团内部赛的时候,评测程序读和写key的顺序是一致的,有局部性效应,采用buffer io,走Page Cache,操作系统的预读read ahead会起作用,会快不少。而外部赛,修正了这个问题,所以buffer io,read ahead反而是糟糕的,预读了很多无用的数据到Page Cache浪费了带宽。
读采用direct io,Java通过JNA使用direct io,需要先通过int posix_memalign(void **memptr, size_t alignment, size_t size)函数对齐内存(内存暂叫做MemPointer),然后通过pread(fd, MemPointer, 4096, offset)系统调用来读取到MemPointer地址,然后拷贝到user space的heap中,这个过程是需要加锁的,如果无锁化就需要池化MemPointer,实测两种方案差距不大。
这里有一个小点可以避免频繁的Young GC,64个线程通过ThreadLocal读4k value,避免频繁的分配内存(感谢@岛风同学的提醒才想到这点,岛风是另外一位Java选手,他的分享见链接)。
这部分是所有3个环节中和C++差距最大的,吞吐2.35G/s,小于C++的2.49G/s,这140MB/s的差距可以归结为建索引慢,通过JNA走JNI的direct io不如直接使用系统调用。
全程young gc 4-5次,无full gc。
6. 实现分析-Range
这是本次比赛拉开差距的环节。题目64并发Range2次,128次full scan,基本不可能,一般有两种思路解决,第一搭车模型,64并发wait,异步线程visit回调;第二64线程齐头并进visit。我这里采用了前者,利用java.util.concurrent并发编程库实现了一个AccumulativeRunner的工具类。
基本思想就是并发的Range请求达到,然后都submit一个Range Task并且wait阻塞,后台有两个触发条件,满足一定Range Task数量,或者超时了例如5s,就trigger一次Range进行full scan,然后回调所有Range请求的visitor,scan完统一的notify Range请求线程解除阻塞。再进行第二次range。时序图如下,
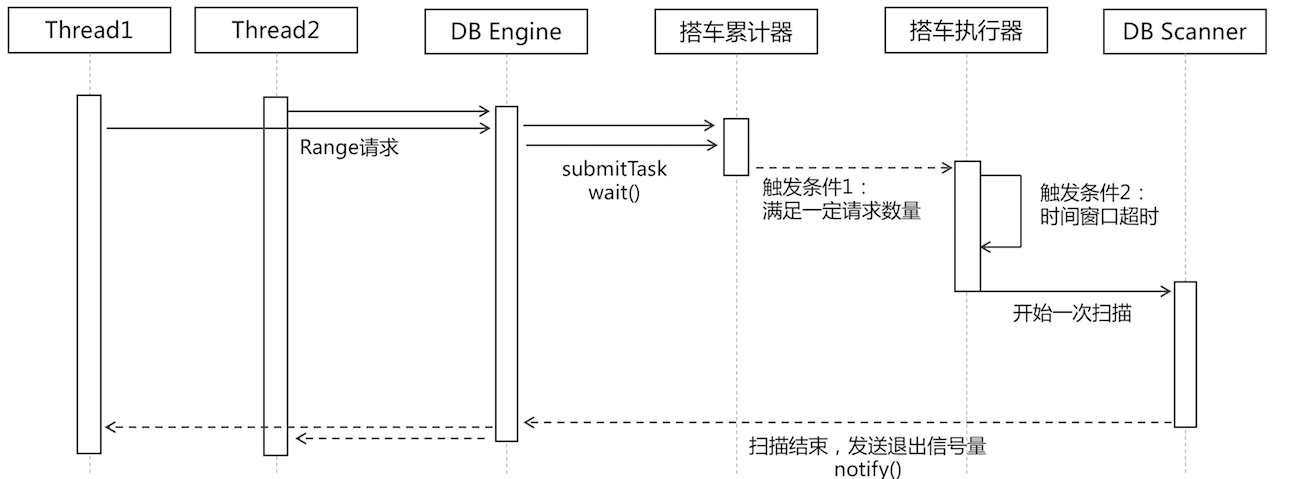
接下来,考量如何高效的进行一次full scan,一开始采用“滑动窗口+并发随机IO查询”的思想,想利用SSD的并发随机IO特性,结果不够理想,第一,走buffer io,利用Page Cache读取数据不如一次性大块IO的load到内存里吞吐高,第二,Java的FileChannel内部有把position的锁,制约性能发挥。
之后放弃了这种模型,转为“滑动窗口+并发内存查询”的思想,效果不错,接近打满带宽。由于key按照字典序分了1024个分片,基本思想就是顺序遍历1024个分片,每个分片放到内存中访问,无缝的衔接每个分片,走完即可。每个分片的访问都分为3个步骤。
1)prefetch预读:wal排序好建立索引,vlog load到内存。
2)Range读取:iterate排序好的wal,针对每个key和vlog seq找value,就变成了内存访问,也就是“并发内存查询”的精髓。
3)评测程序visit:评测程序需要验证有序、值正确等,也有一定消耗。
为了无缝衔接1024个分片做上述3个步骤,使用滑动窗口,如下图,滑动窗口分为5类:
- – 已访问结束的
- – 正在Range读取的和visit的
- – prefetch预读结束,准备被读取的
- – prefetching中
- – 未访问的
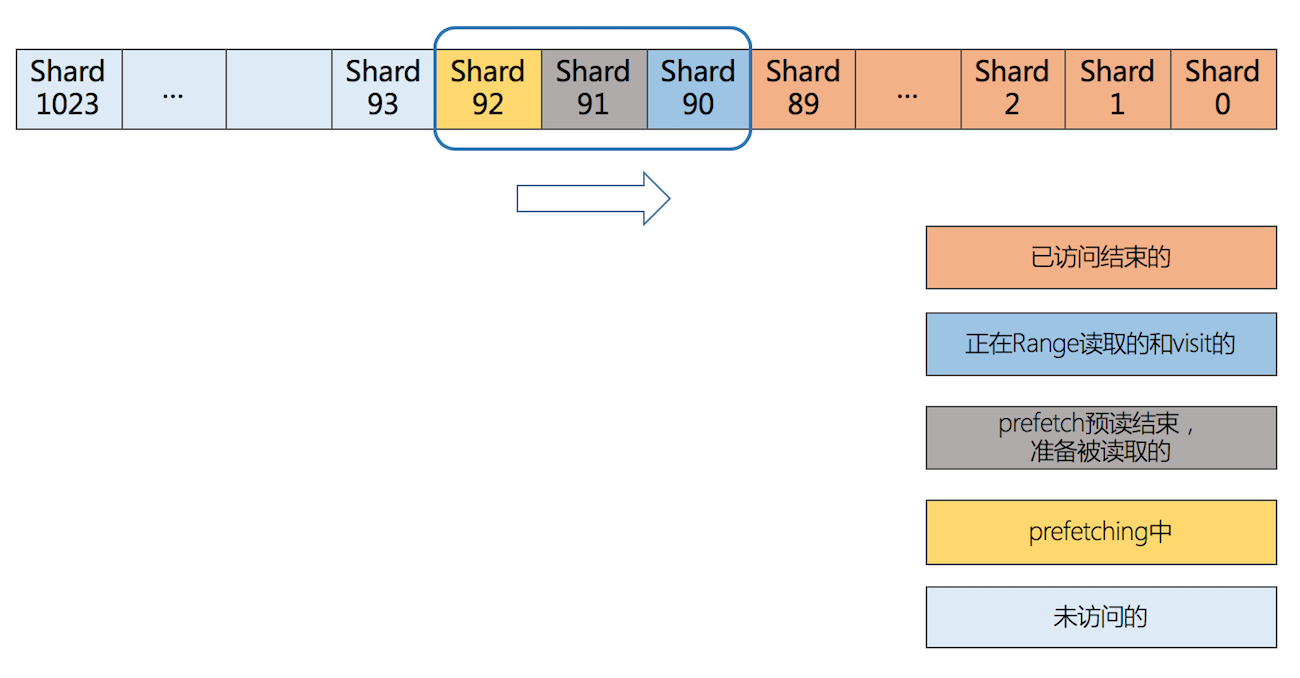
滑动窗口最大容量是3个分片,占用内存最大=vlog(256MB*3)+wal索引(750KB*3)=770MB,这样可以保证不会打破cgroup的内存限制。
prefetch预读,Range读取,评测程序visit三者的瓶颈最终应该在prefetch上,才会打满带宽。所以对于后两个环节,benchmark everything实测确实可能拖后腿,上老办法,串行转并行,做一个多级流水线的架构。
prefetch预读每个分片,就是wal排序好建立索引和load vlog并缓存的过程,这两个过程可以并行。
建立索引,load wal或者wal.sort文件到内存,和read阶段一样,排序好的key和vlog seq放到堆外内存做索引,为Range读取使用。
load vlog并缓存,这个过程可以加并发,单分片vlog大小是256MB,采用8并发*32M大块IO读的方式并行load。load vlog可以选择mmap/file channel/direct io load,实测direct io load和file channel差距不大,最终load vlog文件采用direct io。缓存可以采用offheap DirectBuffer/Unsafe手工分配的内存/heap中,offheap direct memory/Unsafe差距不大,如果使用DirectBuffer,那么后续内存查询get操作非线程安全,所以需要转换为address,通过Unsafe的copyMemory API来访问,进行无锁化;由于load vlog采用direct io,所以这里池化MemPointer,预先在内存中分配出3窗口*8并发共24个32MB的MemPointer,之后read就可以并发无锁的读内存地址了。
Range读取,批量读取256个kv,2个并行即可,然后把结果放到一个无锁队列中。评测程序visit函数在单独的线程中完成,poll无锁队列,针对读取到的kv数据,4个并行的完成64个visitor的回调。这样这两个步骤不至于拖后腿。
对于已经访问结束的分片,需要释放资源,包括wal索引和vlog缓存,以及归还MemPointer到池中。
7. Java实现的特殊性
Java相比C++在比赛中存在一定劣势,这也是直接导致尽管Java排名第一,但是总排名20的原因,虽然和C++第一名的差距只有2.1%,不到9s,但是能做到这样的成绩自己也是比较满意了。
JVM相比C++的劣势包括:
1)不够贴近底层,隔着一层JVM,靠JVM解释字节码执行,虽然有JIT帮热点代码优化为native code执行,但终究不够直接。
2)有GC overhead,如果缓存放heap,必然gc频繁,影响吞吐;并发GC和用户线程可以缓解,必须控制只young gc,不full gc,这个比赛是比IO,所以CPU理论都够用,观察看占400%-600%的CPU是中位数。
3)使用操作系统API不够方便,比如direct io原生JDK不支持,mmap释放内存不方便,线程bind CPU core不方便等。
作为Java选手要克服上面的困难,必然要使出一些大杀器,下面依次总结下。
1、mmap
帮助写入阶段写wal,保证crash consistency。JDK提供原生的API,但是释放相对麻烦。
2、direct io
JNA封装,或者使用jaydio,拼接小IO为大块IO写入。FileChannel在本次比赛都没有使用,原因就是内部有个position lock并且走buffer io,在这个场景不适合,但是大多数Java涉及IO的场景,NIO的FileChannel都是首选。
3、堆外内存
offheap可以用DirectBuffer,或者Unsafe的malloc、free。
4、gc控制
比赛用参数如下,
-server -XX:-UseBiasedLocking -Xms2000m -Xmx2000m -XX:NewSize=1400m -XX:MaxMetaspaceSize=32m -XX:MaxDirectMemorySize=1G -XX:+UseG1GC
write和read阶段young gc都很少,主要为range阶段使用,由于使用了多级流水线架构,所以吃内存比较严重,young gc相对频繁,但没有full gc所以可接受。
5、池化技术
DirectMemory先分配好,然后池化,使用时候反复擦写,可以复用资源。read阶段用ThreadLocal复用value避免频繁young gc。
6、锁控制
kv分离的写入,必然加锁。read阶段的direct io load同一块内存,然后返回给user space的过程也需要加锁,尽量小的控制锁粒度,分散锁的冲突,就像ConcurrentHashMap思想一样,就可以把锁的消耗降到最低。
7、并发利器
java.util.concurrent要用好,Range阶段的搭车模型,并行load vlog,滑动窗口都用到了线程池、lock、condition、mutex等。同时一些无锁并发的类库例如ConcurrentLinkedQueue,jctools的MpmcArrayQueue,disruptor的无锁队列也可以尝试,比赛中都有实验,其实无锁就足够了,瓶颈在IO,这些可以忽略。
8、减少上下文切换
由于比赛使用了Alijdk,而Alijdk有个Wisp API,可以做Java协程,在一些资源释放无需等待的场景可以使用,亲试后通过vmstat -w 1命令看cs列确实少了一些,但是对提高成绩没有很大帮忙。
8. 单机数据库引擎思考
第一,个人认为影响一个数据库性能的方面,存储架构设计 大于 引擎实现质量 大于 语言选型,所以Java在这道题目和C++没有质的区别。
第二,在平台应用服务领域,Java优势在于工程化,类库丰富,设计模式等特性,所以空间广阔;而分布式计算领域,对比HDD和SDD的差距从ms到us数量级的提升,分布式调用同机房ms级别、跨地域几十ms的延迟,才是大问题,所以很多的开源大数据项目,例如spark、hadoop、flink等多采用Java这种工程化好和易维护的语言,也同样满足需求。
第三,存储引擎实现语言的考量:
1)工程化,例如是否static type & 抽象设计
2)Tail latency控制
3)Runtime overhead
Java,2、3对比C++是java的弱项,比如GC和JVM的overhead,但是这两点却是一个DB的刚需。另一个角度,从系统分层角度出发,对2、3敏感的C++,Rust合适,如果是对工程化要求更高Java、Go是有其使用场景的。
9. 总结
第一次参加工程性质的比赛,有各路的高手,大家争秒夺毫秒的比拼,非常刺激,也第一次系统性的实践了一把Java IO相关的技术,学习和积累经验的目标已经达到。希望未来自己还能有精力和活力参加比赛,向高手们学习,切磋进步。技术的路很长,每一步的积累都是为了明天更好的自己,与正在读此文的你共勉。
转载时请注明转自neoremind.com。
看到 博主的 思路感觉自己学的java 只是边边角角,谢谢博主放出这么好的文章
共勉,一起加油!
load vlog采用direct io , 为什么不直接缓存到heap里面, 而要通过unsafe.copyMemory()再复制到heap中,求指教哈
“load vlog采用direct io”,可以直接缓存到heap里面? 就不用再用unsafe.copymemory()了
第三阶段vlog是每个分片加载到堆外内存的,使用direct io方式,所以不在heap。访问这个堆外内存方式可以用Unsafe提供的copyMemory方法。
请问vlog 用mmap 或者pwrite之类的buffer io, 会比direct io慢多少呢?
具体损失多少可以benchmark下,可以从源码的类里面改变一下实现就行,从这种场景下分区DirectIO是快一些的,而且还不用清理page cache。
厉害!不得不服!请问文章可以转载吗?会在显著位置注明作者和出处。
可以的,分享知识,著名出处即可。
大佬您好,最近对分布式存储很感兴趣,不知道从哪里学起,看到您这篇文章,感觉太帅了。不知道博主可否指点一二关于分布式存储如何学习。
先存储,再分布式,可以找一个感兴趣的开源项目切入,很多知识都是相通的。
org.rocksdb
rocksdbjni
5.13.4
pom里面还用这个干嘛的? 不是不让用么?
没用,最开始测试时候加入,忘记删除了。
感谢分享。看完想法是,转给那些说学底层没用的人看看==