
LMAX Disruptor深度解析 – 从硬件共情到无锁并发设计
1. 什么是Disruptor
https://github.com/LMAX-Exchange/disruptor/
参考2011年发表的论文LMAX Disruptor: High performance alternative to bounded queues for exchanging data between concurrent threads,标题即介绍了Disruptor。那么具体实现论文里也一句概括了:
A pre-allocated bounded data structure in the form of a ring-buffer
Disruptor是一个高性能的并发数据结构,通过ring buffer作为bounded queue用于线程间交换消息,支持单/多生产者 对 单/多消费者。
2. API使用简介
先看使用方式。
int bufferSize = 1024; // 设置ring buffer大小 // 创建Disruptor // 假设用LongEvent类作为ring buffer上生产和消费的数据类型,可以自定义任何类型 Disruptor disruptor = new Disruptor<>(LongEvent::new, bufferSize, DaemonThreadFactory.INSTANCE); // 定义event handler,告诉Disruptor如何消费消息事件 disruptor.handleEventsWith(new LongEventHandler()); // 启动 disruptor.start(); |
消费消息的逻辑定义在handler里,比如这里只打印下。
public class LongEventHandler implements EventHandler { @Override public void onEvent(LongEvent event, long sequence, boolean endOfBatch) { System.out.println("Event: " + event); } } |
生产消息的方法如下。
方式1:
RingBuffer ringBuffer = disruptor.getRingBuffer(); // 获取ringbuffer引用 // 要发布的LongEvent默认和一个发布消息事件的sequence绑定 // 因为LongEvent已经pre-allocate到了ring buffer上,所以这里就是设置了一个新的值 ringBuffer.publishEvent((event, sequence) -> event.set(99L)); |
方法2(legacy方式):
long sequence = ringBuffer.next(); // 递增可发布下一个消息事件的sequence LongEvent event = ringBuffer.get(sequence); // 获取这个sequence在ring buffer上对应的LongEvent event.set(99L); // 设置了一个新的值 ringBuffer.publish(sequence); //发布消息,消费者可见 |
3. 为什么Disruptor如此高性能?
总结来说,Disruptor克服了传统linked list以及bounded array list做queue的缺点,站在了CPU角度去优化,论文里提到了一个词叫做“mechanical sympathy”,也就是与硬件共情,也正是当下流行的software hardware co-design。
现代CPU的构造,多核的基础上,每个CPU core和内存之间夹着多级缓存,指令缓存L1i, 数据缓存L1d, L2, L3。每一层都有着latency的鸿沟,如果访问L1d需要1ns,那么一次内存访问会放大60x-100x的延迟。

参考 CMU 15-445/645 Database Systems (Fall 2024) – 03 – Database Storage: Files & Pages
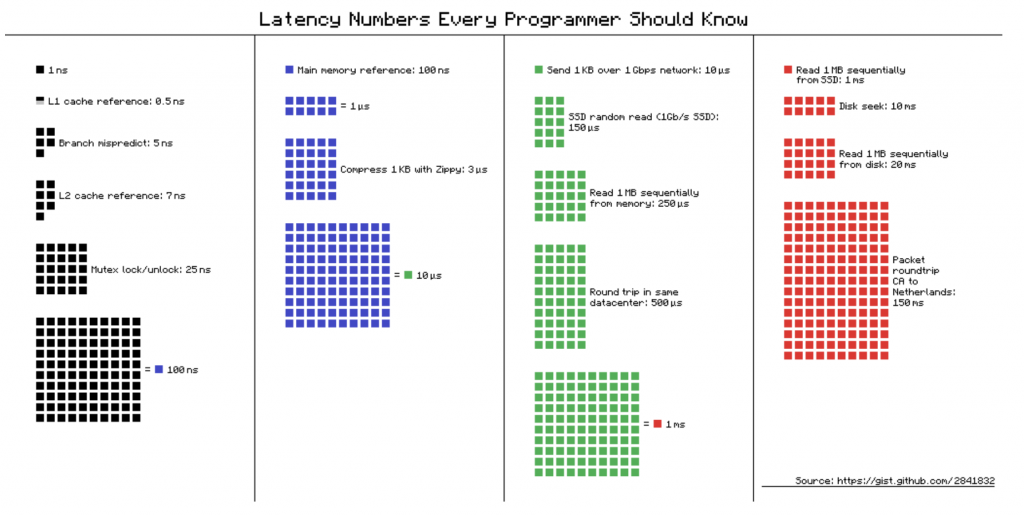 参考Latency numbers every programmer should know (BTW, 14年前的数据仅做参考)
参考Latency numbers every programmer should know (BTW, 14年前的数据仅做参考)
另外CPU和内存交换数据的基本单元是cacheline,一般64 bytes。
高效的数据结构首先应该是CPU cache和cacheline友好的。数据要做到好的Cache Locality,也就是尽量让CPU对执行要操作的数据“唾手可得”,不让CPU等数据,为此要做到
1)Spatial locality。比如CPU最好可以在L1上加载数据到计算单元,程序的access pattern也最好是CPU友好的,比如连续的访问,这样CPU可以做pre-fetch预加载。
2)Temporal locality。最好热数据在register和各级缓存换入换出不频繁,停留更长时间,否则CPU需要花费更多的时间和各层级cache和主存打交道。
如果CPU不能很快load数据到计算单元,就会造成memory stall,打破CPU的流水线(pipeline),例如在简单的5级流水线模型中,如果发生memory stall,访存阶段会阻塞,导致后续指令无法继续推进,浪费时钟周期。
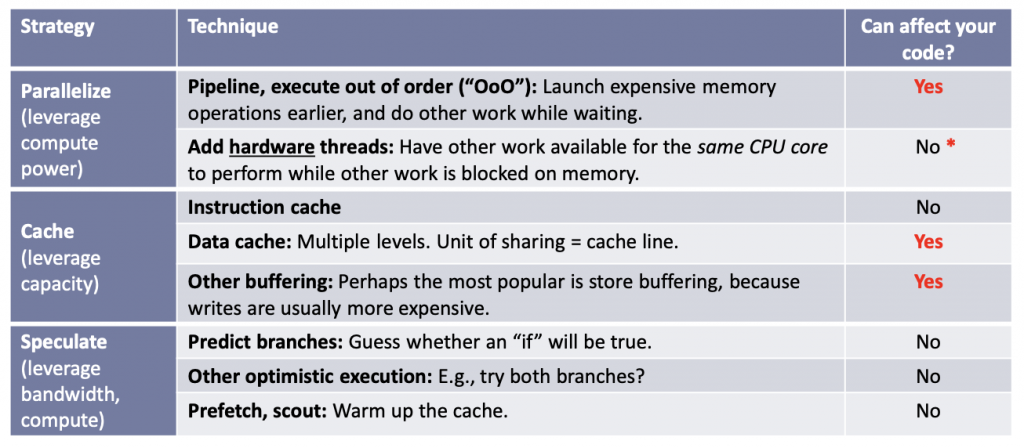
 另外从编译器到CPU会做非常多的优化,因为如果要按照严格的代码执行就抑制啦很多优化,这些优化手段都是维护了一种Sequential Consistency的“幻觉”,从程序角度来说只需要结果执行一致就可。优化手段包括乱序执行,多发射,super scalar执行,分支预测等等,如下图ISO C++ committee主席Herb Sutter在2012年的演讲“C++ and Beyond 2012: Herb Sutter – atomic Weapons”提到的优化策略。其核心思想都是让CPU流水线“忙”起来,真正在做计算。
另外从编译器到CPU会做非常多的优化,因为如果要按照严格的代码执行就抑制啦很多优化,这些优化手段都是维护了一种Sequential Consistency的“幻觉”,从程序角度来说只需要结果执行一致就可。优化手段包括乱序执行,多发射,super scalar执行,分支预测等等,如下图ISO C++ committee主席Herb Sutter在2012年的演讲“C++ and Beyond 2012: Herb Sutter – atomic Weapons”提到的优化策略。其核心思想都是让CPU流水线“忙”起来,真正在做计算。
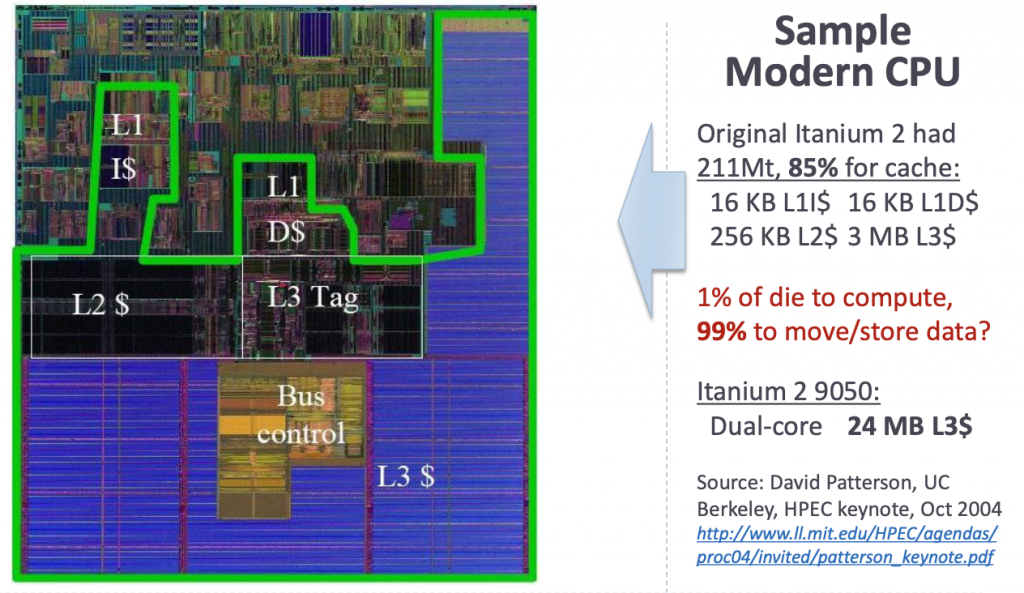
 实际上现代的CPU,面积上大部分都是CPU缓存以及上面提到的各种优化单元,实际ALU做通用计算占比非常低,下图中除了框出来的缓存,上面的部分一大半也是各种优化单元比如branch predictor,SIMD Vector Unit等等。
实际上现代的CPU,面积上大部分都是CPU缓存以及上面提到的各种优化单元,实际ALU做通用计算占比非常低,下图中除了框出来的缓存,上面的部分一大半也是各种优化单元比如branch predictor,SIMD Vector Unit等等。
 回到主题,要实现一个线程交换消息的queue,如果用Linked list实现(Java中的LinkedBlockingQueue),缺点是内存跳跃太多,需要不断的频繁申请内存创建Node实例,维持链表关系,不连续的内存访问会造成cache miss rate升高,CPU访存不友好。那么,Bounded array list(Java中的ArrayBlockingQueue)这方面明显更合适做queue,因为访存更友好,实际ring buffer底层也是一个Bounded array list。那么为什么不直接用Bounded array list呢?
回到主题,要实现一个线程交换消息的queue,如果用Linked list实现(Java中的LinkedBlockingQueue),缺点是内存跳跃太多,需要不断的频繁申请内存创建Node实例,维持链表关系,不连续的内存访问会造成cache miss rate升高,CPU访存不友好。那么,Bounded array list(Java中的ArrayBlockingQueue)这方面明显更合适做queue,因为访存更友好,实际ring buffer底层也是一个Bounded array list。那么为什么不直接用Bounded array list呢?
这里就要引出并发数据结构实现的两个难点:互斥操作(mutual exclusion writes) 和 内存可见性(visibility of change)。
常规的解法是用锁,可以解决上述的难点,在critical section保证一次只有一个线程操作,其他线程等待锁释放再竞争,这种情况lock的消耗会很大,因为会引起context switch,影响CPU的有效利用率。那么既然锁消耗大,自然的想法是使用无锁算法(lock-free),利用CAS(Compare And Swap),还是顺着Bounded array list的思路,核心的变量包含head, tail和size,Bounded array list做queue生产消费模型,push和poll操作需要不断的变更head, tail和size,多核之间为了保证可见性加上需要加上内存屏障(memory barrrier)。例如在x86上保证原子操作和可见性的CAS操作,带有lock前缀的cmpxchg指令是一个完整的内存屏障full fence,这会限制CPU的乱序执行能力和流水线效率,在高度竞争时开销大。另外,这些变量在内存上是相邻,他们三个又小到可以fit到一个cacheline,所有更新都集中在这几个变量,会出现false sharing问题,CPU cache频繁失效进一步影响性能。
- 为此,Disruptor实现了高效的ring buffer数据结构,克服上面的性能问题,秘诀在于:
- 1. 环形数组内存提前分配(比如例子里面的LongEvent),无GC压力
- 2. CPU cache访存locality友好
- 3. 所有代码没有任何形式的锁引入,无锁的设计,单生产者完全无锁,多生产者只需要原子atomic操作,更低的写竞争
- 4. 无false sharing性能影响
- 5. 消费者根据自身需求可以做busy spin, lock-based block, thread yield多种等待策略
4. 核心机制深度剖析
4.1 极简代码的理解
深入Disruptor源代码,整个库代码量仅6000多行。下面用一套极简的的伪代码描述Disruptor的Ring Buffer和消费者。
单生产者:
RingBuffer { int BUFFER_SIZE; // power of 2 long INDEX_MASK = BUFFER_SIZE - 1 Event[] entries // 环形数组,存储实际的消息 Sequence producerSequence Sequence[] consumerSequences long nextSeq void publishEvent(Event eventData) { // 1. 递增sequence nextSeq++ // 2. 检查最慢的消费者是否还没处理完最早的消息(回看ring buffer size大小) wrapPoint = nextSeq - BUFFER_SIZE slowestConsumer = min(consumerSequences) if (wrapPoint > slowestConsumer) { // Buffer full,等待消费者处理完毕最早的消息 wait_for_consumers() } // 3. 可写,写event到ring buffer slot = nextSeq & INDEX_MASK entries[slot] = eventData // 4. 发布sequence (消费者可见,消费者会巡查这个producer的cursor) producerSequence.set(nextSeq) // 这里需要Release fence notify_consumers() // 只针对被阻塞的consumer,对于自旋busy spin的无效 } long getHighestPublishedSequence() { return producerSequence.get() } } |
多(线程)生产者:
RingBuffer { int BUFFER_SIZE; // power of 2 long INDEX_MASK = BUFFER_SIZE - 1 Event[] entries // 环形数组,存储实际的消息 Sequence producerSequence int[] availableBuffer Sequence[] consumerSequences function publishEvent(Event eventData) { // 1. 递增sequence,无竞争,仅仅atomic修改 // 所以多生产者在多线程写event的情况下,可以乱序发布消息 long current = producerSequence.getAndAdd(1); long nextSeq = current + 1; // 2. 检查是否最慢的消费者是否还没处理完最早的消息(回看ring buffer size大小) wrapPoint = nextSeq - BUFFER_SIZE slowestConsumer = min(consumerSequences) if (wrapPoint > slowestConsumer) { // Buffer full,等待消费者处理消息 wait_for_consumers() } // 3. 写event到ring buffer slot = nextSeq % BUFFER_SIZE entries[slot] = eventData // 4. 虽然步骤1发布了sequence,但是这里决定消费者是否可见 // 这里需要Release fence availableBuffer[nextSeq & INDEX_MASK] = nextSeq >> shift; // shift is log2 of BUFFER_SIZE notify_consumers() // 只针对被阻塞的consumer,对于自旋busy spin的无效 } long getHighestPublishedSequence() { 遍历局部的availableBuffer返回可被允许消费的最大的sequence number; } } |
消费者:
function consumeEvents() { // 支持多消费者,这里假设是其中之一 nextToProcess = consumerSequence.get() + 1 while (true) { // 1. 找到producer连续的available的可被消费的消息 // 这里因为多生产者允许乱序生产,所以小trick是截止到“空洞(unavailable消息)”前 wait_producer() availableSeq = RingBuffer.getHighestPublishedSequence() if (availableSeq >= nextToProcess) { // 2. 批量处理消息 for (seq = nextToProcess; seq <= availableSeq; seq++) { slot = seq % BUFFER_SIZE eventData = RingBuffer.entries[slot] handleEvent(eventData) // handler call back,处理消息的逻辑 } // 3. 更新consumer sequence consumerSequence.set(availableSeq) // Acquire fence让生产者感知消费进度 nextToProcess = availableSeq + 1 } else { // 没有任何消息可处理 - block wait or busy spin wait_strategy() } } } |
可以看到核心就是围绕一个Sequence数据结构,这个Sequence里面保存了生产者和消费者的一个long类型的序号,表示生产进度和消费进度,sequence是一直递增的。而ring buffer是实际的物理存储,每个发布的event都需要落在这个ring buffer的某个slot槽位上,位“&”操作会非常快,ring buffer size需要是2的幂,sequence只需要位“&”操作就可以找到归属的slot。当sequence超过BUFFER_SIZE,slot会循环覆盖(ring),走到头就折回来。所以ring buffer实际就是一个bounded array list。生产者和消费者都维护自己的Sequence,用于记录我生产到了什么位置(write pointer),以及我消费到了什么位置(read pointer),单调递增的sequence需要在物理的bounded array list上不断的前进,因此最慢的消费者必须赶上生产进度,否则buffer full生产者会阻塞。
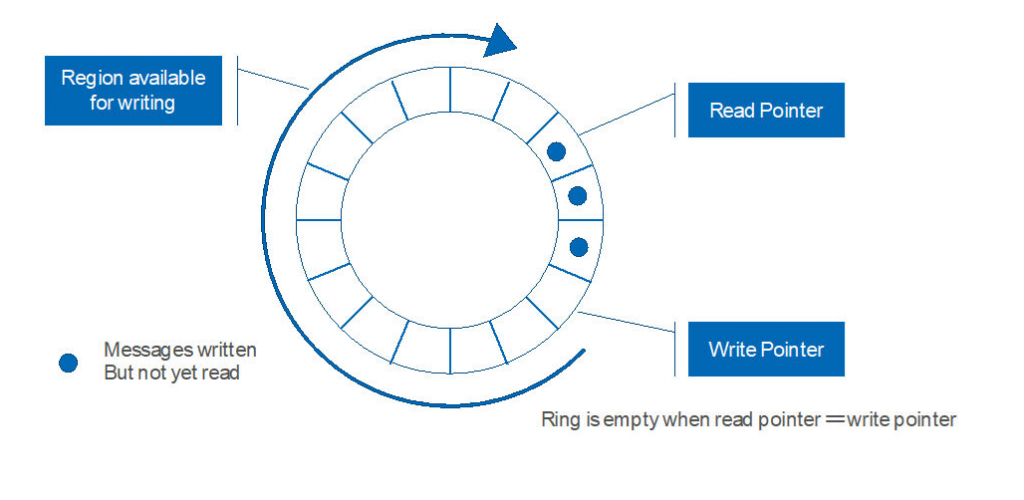 图片参考Herlihy’s “The Art of Multiprocessor Programming”
图片参考Herlihy’s “The Art of Multiprocessor Programming”
下面展示了一个producer领先consumer 3个sequence的例子。
RingBuffer (size = 8) +----+----+----+----+----+----+----+----+ | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | +----+----+----+----+----+----+----+----+ ^ ^ producerIndex=1 consumerIndex=6 Proucuder Sequence = 65 Consumer Sequence = 62 |
4.2 Ring Buffer与Sequence
Sequence结构里面封装了一个简单的long value作为序号。为了避免false sharing,在value字段前后添加了56 bytes(或者7个long)的padding,确保value独占一个cache line。
class Sequence { protected byte p10, p11, p12, p13, p14, p15, p16, p17, p20, p21, p22, p23, p24, p25, p26, p27, p30, p31, p32, p33, p34, p35, p36, p37, p40, p41, p42, p43, p44, p45, p46, p47, p50, p51, p52, p53, p54, p55, p56, p57, p60, p61, p62, p63, p64, p65, p66, p67, p70, p71, p72, p73, p74, p75, p76, p77; protected long value; protected byte p90, p91, p92, p93, p94, p95, p96, p97, p100, p101, p102, p103, p104, p105, p106, p107, p110, p111, p112, p113, p114, p115, p116, p117, p120, p121, p122, p123, p124, p125, p126, p127, p130, p131, p132, p133, p134, p135, p136, p137, p140, p141, p142, p143, p144, p145, p146, p147, p150, p151, p152, p153, p154, p155, p156, p157; } |
深入Sequence,以单生产者为例,如果要发布某个消息event,直接单调递增这个sequence的long value,假设一个producer不断发布event,那么每个发布event都跟随一个调用next(1)方法,sequence+=1更新,set sequence方法如下。
/** * Ensures that loads and stores before the fence will not be * reordered with stores after the fence. * * @apiNote Ignoring the many semantic differences from C and C++, this * method has memory ordering effects compatible with * {@code atomic_thread_fence(memory_order_release)} */ public void set(final long value) { VarHandle.releaseFence(); this.value = value; } |
同样,每个消费者维护了一个Sequence结构记录自己的消费进度也就是sequence,消费者去试探生产者的sequence,如果大于自己维护的进度就表示有新消息,去取ring buffer对应的slot上的event即可。试探就需要下面的get()方法去观察生产者的sequence。
上面消费者伪代码中wait_producer()的实际实现如下,以消费者busy spin的等待策略为例:
public long waitFor( final long sequence, final Sequence cursor, final Sequence dependentSequence, final SequenceBarrier barrier) throws AlertException, InterruptedException { long availableSequence; // dependentSequence可以看作是producer的sequence // 如果生产者没有任何新消息,就不断循环判断,直到有消息 while ((availableSequence = dependentSequence.get()) < sequence) { barrier.checkAlert(); Thread.onSpinWait(); } return availableSequence; } |
这里需要不断试探producer,调用sequence的get()方法。
/** * Ensures that loads before the fence will not be reordered with loads and * stores after the fence. * * @apiNote Ignoring the many semantic differences from C and C++, this * method has memory ordering effects compatible with * {@code atomic_thread_fence(memory_order_acquire)} */ public long get() { long value = this.value; VarHandle.acquireFence(); return value; } |
注意上述的set/get方法是带有内存屏障的(memory barrier)的读写,使用release fence(store fence)和acquire fence(load fence)。如ISO C++ committee主席Herb Sutter在C++ and Beyond 2012: Herb Sutter – atomic Weapons演讲中提到的,对内存屏障最好的理解就是,他们是告诉编译器和CPU这些变量是多线程共享的,所以对于乱序处理和可见性有特殊要求,告诉编译器和CPU我的意图,所以内存模型(memory model)就是一种程序员和系统之间对于多线程处理达成的规范约定。


Release store fence保证了生产者的发布顺序,保证内存屏障之前的event消息更新操作必须先执行,不能被排序到屏障后面。所以发布这个sequence,必然这个sequence之前的event写入不能被乱序挪到sequence发布之后,这样会导致发布了sequence但是event没更新,如下所示这两个操作不能被编译器和CPU out of order执行。
ringBuffer[slot] = eventData; // Write data to ring buffer sequence.set(newSequence); // Signal completion |
有意思的是,根据Dekker algorithms,这个写屏障后面的读实际可以被乱序到这个store之前,在Intel® 64 Architecture Memory Ordering White Paper提到了不同地址的操作的stores → loads,后面的load可能会被乱序排到前面(Loads may be reordered with older stores to different locations but not with older stores to the same location)。如果严格有一个屏障,严格“分开”屏障前后的任何读写,那么就需要full fence,相比store fence就“重(expensive)”了很多。这也是为什么Disruptor不把value做成一个volatile变量,因为volatile变量在Java内存模型中保证了对该变量的每次读写都具有完全的顺序一致性(Sequential Consistency) 语义,需要更强的内存屏障full fence。而Disruptor通过VarHandle.releaseFence()和acquireFence(),可以更精确地控制内存序,仅在需要的地方插入release(针对生产者) 和acquire(针对消费者) 屏障,这是一种更细粒度、开销更低的同步方式,满足了追求极致性能的目标。
对于x86,满足TSO,天然不会有store-store乱序,但是这个release store fence有一个其他重要的作用是刷store buffer到CPU cache hierarchy,参考Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3A: System Programming Guide, Part 1 12.10章节的描述,如果你作为程序员告诉编译器和操作系统这里加入sfence,就意味着要刷store buffer,尽快发布出去变更,不要等Intel CPU自己的MESI缓存一致性协议达到最终一致。
12.10 STORE BUFFER
Intel 64 and IA-32 processors temporarily store each write (store) to memory in a store buffer. The store buffer
improves processor performance by allowing the processor to continue executing instructions without having to
wait until a write to memory and/or to a cache is complete. It also allows writes to be delayed for more efficient use
of memory-access bus cycles.
In general, the existence of the store buffer is transparent to software, even in systems that use multiple proces-
sors. The processor ensures that write operations are always carried out in program order. It also ensures that the
contents of the store buffer are always drained to memory in the following situations:
• When an exception or interrupt is generated.
• (P6 and more recent processor families only) When a serializing instruction is executed.
• When an I/O instruction is executed.
• When a LOCK operation is performed.
• (P6 and more recent processor families only) When a BINIT operation is performed.
• (Pentium III, and more recent processor families only) When using an SFENCE instruction to order stores.
• (Pentium 4 and more recent processor families only) When using an MFENCE instruction to order stores.
The discussion of write ordering in Section 9.2, “Memory Ordering,” gives a detailed description of the operation of
the store buffer.
同时Memory Barriers: a Hardware View for Software Hackers论文也想洗描述了“The memory barrier smp_mb() will cause the CPU to flush its store buffer before applying each subsequent store to its variable’s cache line.”
回到Disruptor,加了store fence表示,set sequence之前的event更新,以及set sequence本身都发布出去,同时如果此时这个变量在Intel MESI缓存一致性机制里面处于shared状态,其他某个消费者运行在的CPU也share了这个变量,那么就发snoop invalidate通知到其他CPU,这样一旦release set执行完毕,发生在该操作之后对应的acquire read都可以读到最新的值,那么就需要从其他CPU或者主存获取最新值。另外,acquire read避免了之后操作的重排序,包括write和store(相当于Load-Load + Load-Store fence),也就是读取生产者发布的event,不能被乱序到对应的acquire load sequence前面,然而x86 TSO天然不会乱序,但是对于其他架构例如ARM是添加了保障的。release/acquire是需要成对出现的,构成一个synchronize-with同步点,否则无法保证顺序性和可见性。
以x86举例来说,假设这个sequence在CPU1上是生产者,在CPU2上是消费者,初始状态MESI都是shared,那么具体的处理timeline可以简单理解如下。
T1: CPU1(生产者)执行 VarHandle.releaseFence() release store写 └─ releaseFence阻止fence前写与后续操作重排 └─ Store buffer drain到L1对应的cache line(不必写回内存),包括发布的event和sequence更新 └─ 发送Invalidate message(snoop invalidate)给CPU2并等待ack └─ L1 Cache Line从Shared升级为Modified T2: CPU2执行VarHandle.acquireFence() acquire load读取 └─ acquire 阻止后续读/写重排到该读之前 └─ CPU2发现旧数据的Cache Line变为Invalid └─ 触发Cache miss T3: CPU2从CPU1做cache-to-cache获取最新Cache Line或者CPU2从L3/主存获取(假设已回写) └─ CPU1将Modified数据回传或写回 └─ CPU1的Cache Line状态降级为Shared,CPU2的Cache Line变为Shared T4: CPU2读取数据 └─ 从本地Cache Line读取到Shared状态的最新值 |
注:
1. Memory Barriers: a Hardware View for Software Hackers论文有非常权威和直观类似timeline的理解。 https://www.puppetmastertrading.com/images/hwViewForSwHackers.pdf
2. Faster Core-to-Core Communications https://www.intel.com/content/www/us/en/developer/articles/technical/fast-core-to-core-communications.html 提到了snoop invalidate。When a core wishes to write, and the state is not exclusive, the core must ask the home agent for permission. If any other caches have copies, the home agent sends them “snoop invalidate” messages. Once those are acknowledged, the home agent sends the requesting cache permission to enter an exclusive state.
4.3 多生产者中的逻辑
对于MultiProducerSequencer,其实例变量包含:
private static final VarHandle AVAILABLE_ARRAY = MethodHandles.arrayElementVarHandle(int[].class); private final Sequence gatingSequenceCache = new Sequence(Sequencer.INITIAL_CURSOR_VALUE); // availableBuffer tracks the state of each ringbuffer slot private final int[] availableBuffer; private final int indexMask; private final int indexShift; |
一次发布event需要经过next()和publish()方法。
public long next(final int n) { // 递增,获取下一个位置的sequence,这里非常重要,仅仅atomic操作即可,降低写竞争。 long current = cursor.getAndAdd(n); long nextSequence = current + n; long wrapPoint = nextSequence - bufferSize; long cachedGatingSequence = gatingSequenceCache.get(); if (wrapPoint > cachedGatingSequence || cachedGatingSequence > current) { long gatingSequence; while (wrapPoint > (gatingSequence = Util.getMinimumSequence(gatingSequences, current))) { LockSupport.parkNanos(1L); // TODO, should we spin based on the wait strategy? } gatingSequenceCache.set(gatingSequence); } return nextSequence; } public void publish(final long sequence) { setAvailable(sequence); waitStrategy.signalAllWhenBlocking(); } // 获取所有消费者中消费最慢的消费者对应的sequence // 当ring buffer满的时候,生产者生产的event不能发布,必须保证不能overwrite,不能“超过”最慢的消费者 public long getMinimumSequence() { return Util.getMinimumSequence(gatingSequences, cursor.get()); } // --- private方法 --- private void setAvailable(final long sequence) { setAvailableBufferValue(calculateIndex(sequence), calculateAvailabilityFlag(sequence)); } private void setAvailableBufferValue(final int index, final int flag) { AVAILABLE_ARRAY.setRelease(availableBuffer, index, flag); } private int calculateIndex(final long sequence) { return ((int) sequence) & indexMask; } private int calculateAvailabilityFlag(final long sequence) { return (int) (sequence >>> indexShift); } |
这里面的优化点包括:
-
1. getAndAdd原子操作
next()方法从git history上,之前使用了acquire load sequence + 复杂逻辑 + CompareAndSet,高冲突下的带有复杂中间逻辑CAS操作会导致更多的cpu消耗。目前的实现降低了多线程的竞争,cursor.getAndAdd(n)表示生产者要求ring buffer腾出位置“准备”发布event,在多线程的情况下,仅仅通过一次atomic操作(虽然底层也是CAS),多个线程都可以获取自己所claim的slot segment,然后写入events。此时消费者实际可以感知到生产者的sequence前进了,但是实际决定是否消费还需要check availableBuffer。
-
2. 乱序写和消费者观察
虽然消费者此时可以观察到生产者的sequence,但是决定是否能消费需要判断isAvailable,因为上面的next()方法允许乱序写入,所以消费者看到的最高可消费sequence可能比实际生产者claim的sequence小,形成“空洞”。为此,对于消费者,需要返回的sequence要截止到“空洞”或者最新的发布,也就是虽然sequence超前了,但是多线程情况下,有些线程还没有及时把events放到对应ring buffer的slot上,通过getHighestPublishedSequence获取这个可能的空洞位置-1的sequence 或者 发布消息的最尾端。
public long getHighestPublishedSequence(final long lowerBound, final long availableSequence) { for (long sequence = lowerBound; sequence <= availableSequence; sequence++) { if (!isAvailable(sequence)) { return sequence - 1; } } return availableSequence; } public boolean isAvailable(final long sequence) { int index = calculateIndex(sequence); int flag = calculateAvailabilityFlag(sequence); return (int) AVAILABLE_ARRAY.getAcquire(availableBuffer, index) == flag; } |
举例,某一时刻有三个生产者,buffer size = 8,producer next sequence = 2。假设生产者线程(A)和(C)先写完了,生产者线程(B)仅仅next成功了,但是event还没有放到slot或者还没有带store fence写成功availableBuffer,此时producer next sequence = 7。availableBuffer是用来让消费者判断某个slot是否可以消费的,消费者读这个数组的某个局部来判断可消费的sequence。如下,消费者仅仅能消费到sequence = 3位置新消息,也就是生产者(A)发布的两条消息,其他两个生产者写的消息暂时不可见,需要经过下一轮再check availableBuffer才能正式披露给消费者。注意这里带release fence写availableBuffer数组的操作是通过VarHandle API实现。
RingBuffer (size = 8) availableBuffer: +---+---+---+---+---+---+---+---+ | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | +---+---+---+---+---+---+---+---+ before: 1 1 0 0 0 0 0 0 after : 1 1 1 1 0 1 1 0 Producers: | A || B || C | |
-
3.缓存最慢的消费者进度
利用cachedGatingSequence缓存了最慢的消费者进度,因为一般ring buffer设置会比较大,不会立刻就写满了,所以这里缓存了最慢的消费者的sequence,避免频繁以O(N)复杂度遍历所有消费者,并且还是带内存屏障load fence的读。优化后,仅仅一次O(1)的普通变量读即可。如果发现了buffer满了,再去最新的consumer消费进度即可。
4.4 消费者等待策略
如果消费者消费很慢,导致生产者无法插入新消息,那么Disruptor的处理策略是让生产者间隔1ns自旋,可以看到这个注释,所以用Disruptor要尽量保证buffer size设置合理。
LockSupport.parkNanos(1L); // TODO, should we spin based on the wait strategy? |
那么看看消费者,这里的等待策略就非常多,这些都是在没有可消费消息时候,消费者的等待策略。比如log4j2就采用了自定义的wait strategy,默认是TimeoutBlockingWaitStrategy,基于锁和周期性超时唤醒,因为如果没有日志要打印,不用消耗多余的CPU。另外log4j2是多生产者和单消费者模式,因为写日志是IO bound的,单个消费者handler顺序写IO效率高。但是对于高频交易,就需要极低延迟保障,通常使用spin wait,但CPU消耗大。
各种lock-based wait and notify, thread yield,busy spin等待策略如下。
BlockingWaitStrategy
TimeoutBlockingWaitStrategy
BusySpinWaitStrategy
YieldingWaitStrategy
SleepingWaitStrategy
4.5 消费者轮训实现
consumer对每个handler都启动了一个线程,注意多个handler是多个线程,所以disruptor支持多生产多消费者。
同时,消费者拿消息是支持批量拿的,这样进一步提升了批量处理的能力。
// 在某个线程中执行handler,可以是chained handler private void processEvents() { T event = null; long nextSequence = sequence.get() + 1L; while (true) { final long startOfBatchSequence = nextSequence; try { try { // wait_producer() final long availableSequence = sequenceBarrier.waitFor(nextSequence); final long endOfBatchSequence = min(nextSequence + batchLimitOffset, availableSequence); // 批量拿消息 if (nextSequence <= endOfBatchSequence) { eventHandler.onBatchStart(endOfBatchSequence - nextSequence + 1, availableSequence - nextSequence + 1); } // 回调handler处理消息 while (nextSequence <= endOfBatchSequence) { event = dataProvider.get(nextSequence); eventHandler.onEvent(event, nextSequence, nextSequence == endOfBatchSequence); nextSequence++; } retriesAttempted = 0; // 更新消费者进度 sequence.set(endOfBatchSequence); } catch (final RewindableException e) { nextSequence = rewindHandler.attemptRewindGetNextSequence(e, startOfBatchSequence); } } catch (final TimeoutException e) { notifyTimeout(sequence.get()); } catch (final AlertException ex) { if (running.get() != RUNNING) { break; } } catch (final Throwable ex) { handleEventException(ex, nextSequence, event); sequence.set(nextSequence); nextSequence++; } } } |
5. Disruptor的工程与设计
5.1 优雅的DSL – Disruptor的抽象层与易用性
如Fundamental theorem of software engineering描述的
We can solve any problem by introducing an extra level of indirection.
一个好的框架就是提供更好的抽象层次让程序员使用,类比Java和Python提供了足够的上层抽象,C++兼顾了上层的抽象和底层的可操作性。很有感触的是C++之父Bjarne Stroustrup在2025年的一次演讲“C++ as a 21st century language – Bjarne Stroustrup”,表达了layers of abstraction的重要性,当你剥洋葱的时候,也就是你peel off拨开越下面的层次,越会感到棘手而辣“哭”了眼睛,因为太底层了。
来看Disruptor,如何屏蔽ring buffer的感知,线程间交换数据,内存屏障等,只需要几行代码,实现消费者的逻辑,然后不断的publish即可,不需要关心底层多线程如何交换,这种another layer of indirection,就是可以让框架易于使用,为此才有这个Disruptor的入口层。
5.2 Clean code和严谨性
Disruptor框架的代码非常优雅,面向对象设计的非常清晰,从最早的UML类图就可以看出来,当然现在相比10多年前,其类组织也进化了一些。
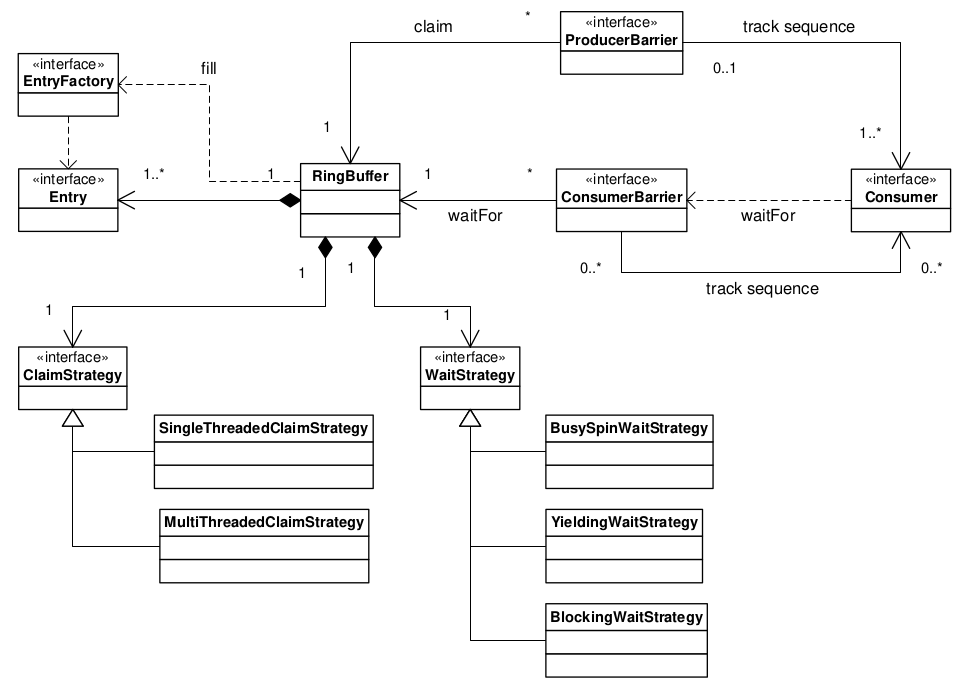 实际我也就深入研究了如下几个类,就可以掌握其精髓。
实际我也就深入研究了如下几个类,就可以掌握其精髓。
Sequencer,Cursored,Sequenced
AbstractSequencer
SequenceGroup
SingleProducerSequencer
MultiProducerSequencer
WaitStrategy
BatchEventProcessor
SequenceBarrier
ProcessingSequenceBarrier
RingBuffer
Disruptor |
另外,核心维护者Nick Palmer在2021年后还添加了jmh做性能测试,jcstress做多线程乱序和内存可见性测试,都保障了框架本身的高性能特质。
参考资料
1. https://github.com/LMAX-Exchange/disruptor/
2. Disruptor technical paper: https://lmax-exchange.github.io/disruptor/disruptor.html
3. CMU 15-445/645 Database Systems (Fall 2024) – 03 – Database Storage: Files & Pages https://15445.courses.cs.cmu.edu/fall2024/notes/03-storage1.pdf
4. Latency numbers every programmer should know https://gist.github.com/hellerbarde/2843375
5. C++ and Beyond 2012: Herb Sutter – atomic Weapons 1 of 2 https://www.youtube.com/watch?v=A8eCGOqgvH4&t=3417s
6. https://en.wikipedia.org/wiki/False_sharing
7. JEP 171: Fence Intrinsics https://openjdk.org/jeps/171
8. Dekker’s algorithm https://en.wikipedia.org/wiki/Dekker’s_algorithm
9. Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3A: System Programming Guide, Part 1
https://cdrdv2-public.intel.com/812386/253668-sdm-vol-3a.pdf
10. Memory Barriers: a Hardware View for Software Hackers https://www.puppetmastertrading.com/images/hwViewForSwHackers.pdf
11. https://github.com/apache/logging-log4j2
12. Fundamental theorem of software engineering https://en.wikipedia.org/wiki/Fundamental_theorem_of_software_engineering
13. Indirection https://en.wikipedia.org/wiki/Indirection
14. Closing Keynote: C++ as a 21st century language – Bjarne Stroustrup https://www.youtube.com/watch?v=1jLJG8pTEBg&t=1466s
15. Intel® 64 Architecture Memory Ordering White Paper https://www.cs.cmu.edu/~410-f10/doc/Intel_Reordering_318147.pdf
16. Volatile and memory barriers https://jpbempel.github.io/2015/05/26/volatile-and-memory-barriers.html
17. Faster Core-to-Core Communications https://www.intel.com/content/www/us/en/developer/articles/technical/fast-core-to-core-communications.html
转载请注明转自neoremind.com