
利用spring的BeanNameAutoProxyCreator做事务管理配置
在项目开发时候,很多目标bean需要生成事务代理,可以为每一个目标bean配置一个 TransactionProxyFactoryBean bean。这样做的话,可能最后变成配置地狱,此时可以考虑使用自动事务代理。
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN&quo[......]<p class="read-more"><a href="http://neoremind.com/2012/05/%e5%88%a9%e7%94%a8spring%e7%9a%84beannameautoproxycreator%e5%81%9a%e4%ba%8b%e5%8a%a1%e7%ae%a1%e7%90%86%e9%85%8d%e7%bd%ae/">继续阅读</a></p> |
python脚本在crontab中无法执行解决
今天在crontab里配置了一个python脚本定时执行,配置信息如下:
# crontab -l 35 9 * * * cd /home/work/test; ./test.py |
结果没有任何输出就是执行不了,利用下面命令观察crontab日志。
# s[......]<p class="read-more"><a href="http://neoremind.com/2012/05/python%e8%84%9a%e6%9c%ac%e5%9c%a8crontab%e4%b8%ad%e6%97%a0%e6%b3%95%e6%89%a7%e8%a1%8c%e8%a7%a3%e5%86%b3/">继续阅读</a></p> |
发现任务按时运行了,问题就奇怪了。
后来想到是不是环境变量引起的,于是检查python脚本的头部,将python的执行命令加入进去就好了,例如:
#!/usr/local/bin/python # cod[......]<p class="read-more"><a href="https://neoremind.com/2012/05/python%e8%84%9a%e6%9c%ac%e5%9c%a8crontab%e4%b8%ad%e6%97%a0%e6%b3%95%e6%89%a7%e8%a1%8c%e8%a7%a3%e5%86%b3/">继续阅读</a></p> |
HTTP Server简介
1. HTTP Server是干什么的?
– 处理http请求,返回数据给浏览器
– 负载均衡/反向代理/健康检查
– 日志(access log)
– URL Rewrite
– gzip
– cache-control(expire,etag,last-modified)
– keep-alive(长连接[……]
分布式应用通信协议
1. 历史
第一轮:HTTP,带来了Internet与电子商务
第二轮:Java,cross-platform,最早的RMI
第三轮:XML,标准的数据封装技术,各种App之间交换数据不再是难事。
第四轮:RPC,Webservice、REST、高性能通信协议
2. What is RPC?
简单理解: 可互操作的Web服务
RPC(Remote Procedure Call)
– 在某种传输协议(TCP\HTTP等)上携带信息数据,通过网络从远程计算机程序上请求服务
– &[……]
跨平台通信中间件thrift学习【Java版本】
1. What is thrift?
2. thrift为我们做了什么?
几种Java常用的通信协议比较
本文比较了RMI,Hessian,Burlap,Httpinvoker,Web service等5种通讯协议的在不同的数据结构和不同数据量时的传输性能。
1. 简介
[……]
WEB小流量实验解决方案
最近在项目组里负责搭建WEB系统的小流量实验平台,这篇文章主要介绍了小流量实验的目的,方法原理,实现方案等。
1. 小流量实验的目的
2. 小流量实验方法论
nginx根据cookie分流
在Linux上利用phantomjs进行网页截图
1. phantomjs介绍
2. phantomjs应用场景
3. phantom网页截图
sudo add-apt-repository ppa:jerome-etienne/neoip[......]<p class="read-more"><a href="http://neoremind.com/2012/03/%e5%9c%a8linux%e4%b8%8a%e5%88%a9%e7%94%a8phantomjs%e8%bf%9b%e8%a1%8c%e7%bd%91%e9%a1%b5%e6%88%aa%e5%9b%be/">继续阅读</a></p> |
MySQL的Infobright引擎介绍
Infobright是一个与MySQL集成的开源数据仓库(Data Warehouse)软件,可作为MySQL的一个存储引擎来使用,SELECT查询与普通MySQL无区别。
基本特征
优点:
1. 查询性能高:百万、千万、亿级记录数条件下,同等的SELECT查询语句,速度比MyISAM、InnoDB等普通的MySQL存储引擎快5~60倍
2. 存储数据量大:TB级数据大小,几十亿条记录
3. 高压缩比:在我们的项目中为18:1,极大地节省了数据存储空间
4. 基于列存储:无需建索引,无需分区
5. 适合复杂的分析性SQL查询:SUM, COUNT, AVG, GROUP BY
[……]
海量用户积分排名的几种算法
问题
某海量用户网站,用户拥有积分,积分可能会在使用过程中随时更新。现在要为该网站设计一种算法,在每次用户登录时显示其当前积分排名。用户最大规模为2亿;积分为非负整数,且小于100万。
PS: 据说这是迅雷的一道面试题,不过问题本身具有很强的真实性,所以本文打算按照真实场景来考虑,而不局限于面试题的理想环境。
存储结构
首先,我们用一张用户积分表user_score来保存用户的积分信息。
表结构:
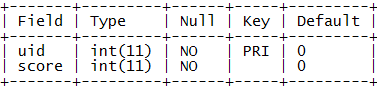
示例数据:
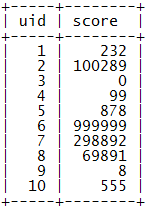
下面的算法会基于这个基本的表结构来进行。
算法1:简单SQL查询
首先,我们很容易想到用一条简单的SQL语句查询出积分大于该用户积分的用户数量:
select[......]网络营销词汇表
网络广告计费模式
CPM:(Cost Per Mille/ ) 每千人成本: 通常用于banner, 图片,flash广告
CPC:(Cost Per Click) 每点击成本: 以每点击一次计费,广泛应用于搜索引擎广告
CPA/CPT:(Cost Per Action/Transaction) 每行动成本: CPA计价方式是指按广告投放实际效果,通常用于在线交易。
除了CPM、CPC、CPA之外,还有:
CPTM (Cost per Targeted Thousand Impressions) :经过定位的用户(如根据人口统计信息定位[……]
召回率与准确率
召回率(Recall Rate)(查全率):是检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率。
精度(Precision)(查准率):是检索出的相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率。
对于一个检索系统来讲,召回率和精度不可能两全其美:召回率高时,精度低,精度高时,召回率低。
对于搜索引擎系统来讲,因为没有一个搜索引擎系统能够搜集到所有的 Web 网页,所以召回率很难计算。
目前的搜索引擎(广告)系统都非常关心精度,而网盟联盟广告系统更关心召回率,因为要出准确的广告。
影响一个搜索引擎系统的性能有很多因素[……]
B树、B+树与B*树简介
本文主要介绍各种B树,不对插入、删除做过多的深入了解。
1. 引子
动态查找树主要有:
查看memcached运行状态
memcache的运行状态可以方便的用stats命令显示。
telnet ip port |
一个实际的执行结果如下:
$ telnet 127.0.0.1 11311 Trying 127.0.0.1 ... Connected to xxx.yyy.ccc.com ( 127.0.0.1 ). Escape character is[......]<p class="read-more"><a href="https://neoremind.com/2012/02/%e6%9f%a5%e7%9c%8bmemcached%e8%bf%90%e8%a1%8c%e7%8a%b6%e6%80%81/">继续阅读</a></p> |