
从服务和存储角度看异地多活的高可用架构
1. 前言
互联网公司的分布式系统要对外提供可靠的服务,一般都会有一套高可用的架构,在CAP理论下,分区容忍性往往是不能舍弃的,所以对于系统可用性(Availability)、数据一致性(Consistency)的容忍程度,决定了能提供什么样的服务等级。简单的系统部署在单地域单机房,但是大型互联网公司,一般都不采用这样的单点架构,从同城双活到异地灾备,再到异地多活。Google在2015所发表的一篇论文《High-Availability at Massive Scale: Building Google’s Data Infrastructure for Ads》也介绍了类似的架构,本文简单介绍下这种架构。
2. 应用的构成和部署
对外提供服务的应用系统,一般由两部分组成:无状态(stateless)的服务,有状态的存储。
无状态的服务一般包含接入层(例如HTTP Server),分布式的微服务。
有状态的存储一般指数据库,NoSQL,缓存等。
这些应用建立在OS上,依赖一些硬件基础设施,是主机、网络、机架、网络、电力等。
基础设施在物理上部署在某个区域(region)的可用区(availbility zone),可用区可看做一个机房(IDC)。
3. 高可用架构的演进
Google这篇论文《High-Availability at Massive Scale: Building Google’s Data Infrastructure for Ads》主要介绍了Ad广告部门是如何做异地多活的。文中提及了一种Avaiblity Tier,也就是可用性的层级,从低到高依次是:
1)单机房(Singly-homed systems)
2)跨机房故障切换(Failover-based systems)
3)异地多活(multi-homed systems)
多数互联网公司都是从类似的架构过渡来的,下面依次展开说明,最后还会单独说有状态的存储是在这种架构里是如何做的。
4. 单机房
对于可用性不高的应用足够了,特别在公有云平台上往往机房的线路、电力、散热都是冗余的,架构上采用集群模式,避免机器、机架故障,出事故的概率不高,但是一旦出事故就只能干等着恢复了,所以对于大型互联网公司,在核心服务上都至少做一个进阶,也就是”同城双活“或者”同城多活“。
5. 同城双活
单机房遇到机房断电、网络故障便停止服务,同城机房可弥补这个弊端。
由于同城机房物理上距离足够近,可以搭建专线连接,服务间做跨机房调用近似同机房。在部署上和单机房相比不做特殊要求。
接口层的DNS、四层设备、反向代理、网关/Web层可以随机路由。
应用层由于是无状态的,用服务化框架连通,服务治理的范围就在这部分,内部可做横向扩展,具备scale out能力,接口层到应用层,或者应用层内部服务路由策略可以自由选择,例如随机、轮询、一致性哈希、sticky session、同机房优先、自定义路由规则等。

存储层先拿数据库做例子,一般互联网公司使用MySQL,主从复制(异步或者半同步),主故障时候可以手工(switch over)或者自动切换(failover)从为主,解决可用性的同时对于RPO(Recovery Point Objective)和一致性都或多或少有损,另外这种架构,对于存储是伪双活的,因为同一时间只有一个Master。另外一种方式是使用分布式数据库,利用Paxos、Raft分布式一致性协议保证强一致。存储这放到后面的章节介绍。

6. 异地灾备(跨地域故障切换)
同区域(同城)的容灾,遇到地震和洪涝等自然灾害时,服务的持续性就会中断。跨地域部署最大的挑战是延迟,一些网络延迟的数据如下:
- 北京-广州 2000公里+ 50ms
- 北京-杭州 1000公里+ 30ms
- 上海-杭州 100+公里 7ms
- 北京多个机房间 3ms
- 同机房 300us
如果服务调用关系复杂,多次的round trip,加上网络的抖动,跨地域部署往往是不能接受的。异地备份可以解决遇到区域挂掉的时候,做冷备、热备切换,保证服务持续性。
接口层、服务层、存储层均独立部署一套。存储层靠活着的(alive)区域进行异步复制。
这种同城双活+异地灾备的架构,可称之为”两地三中心“架构,即两个区域,三个IDC(可用区)。
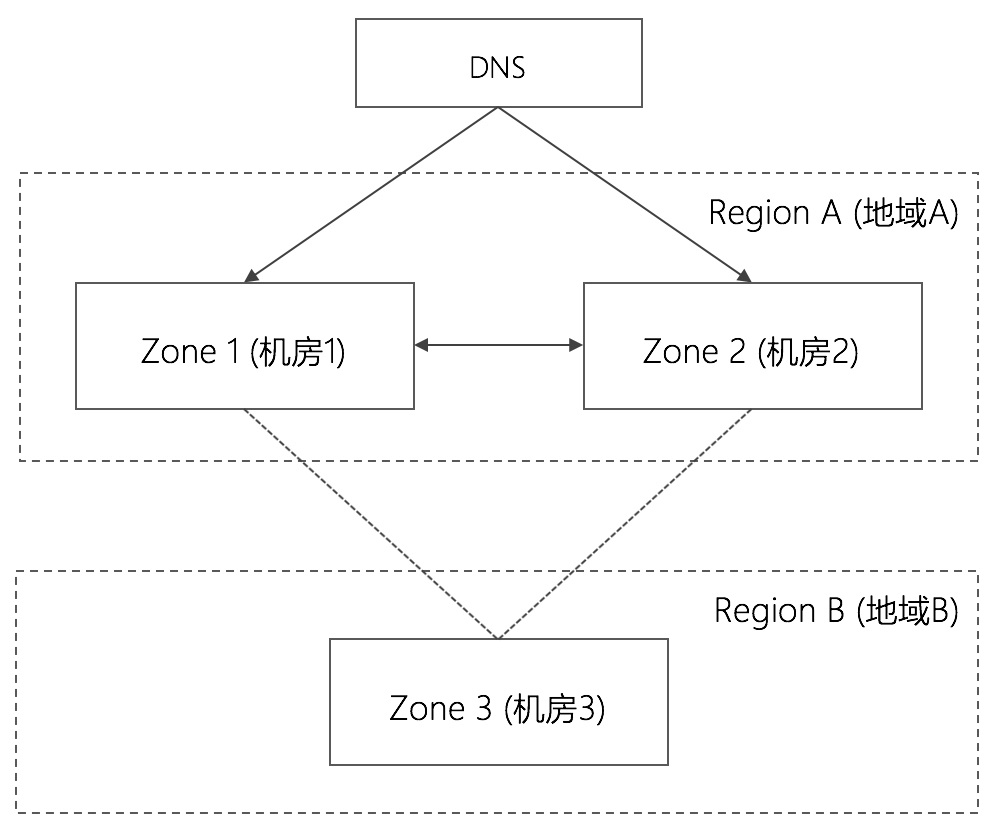
7. 异地多活
同城双活+异地灾备对于中小型应用往往足够了,但是对于大型公司而言,一是数据量极大,二是对于可用性要求极高(5个9的SLA水平全年停服不能超过5min),异地灾备架构的弊端在于:
1)跨地域机房不跑流量,对于数据一致性很高的场景,出事了不敢切。恢复时间(RTO,Recovery Time Objective),取决于方案本身或者预案在当下执行的质量。
2)备份全站,资源利用率低,成本高。
3)伸缩性不好,扩容困难,不具有扩展性,受限于单地域的容量,包括计算、存储、网络资源。
所谓异地多活,就是说在多个不同物理地域之间同时提供业务服务。
各个地域之间不是主备关系,所以不涉及到故障切换failover的工作,《High-Availability at Massive Scale: Building Google’s Data Infrastructure for Ads》里也提及了failover的灾备策略往往不是自动化的,而且一般比较复杂的,需要测试演练的,所以维护的成本、切换的风险也很高。
异地多活下,各个地域独立隔离,业务流量可以不均等的分配到各个地域和可用区里面。与异地冷备相比,
1)具备更快的恢复能力。流量动态分配,一个区域挂掉,流量可以自由的在地域间调度、切换。在某些场景甚至还可以支持就近原则,用户访问更快。预期和非预期的机房故障都可以支持。预期的可以做容灾演练、机房维护,这些都对业务都是透明的。
2)不用备份全站,成本低。
3)扩展性好,数据应用可以shard在各个区域,这种伸缩性是必备的。
这里需要强调下并不是所有业务都需要做异地多活,主链路功能,对可用性有极致要求,规模大的才优先做,否则方案也会比较复杂。
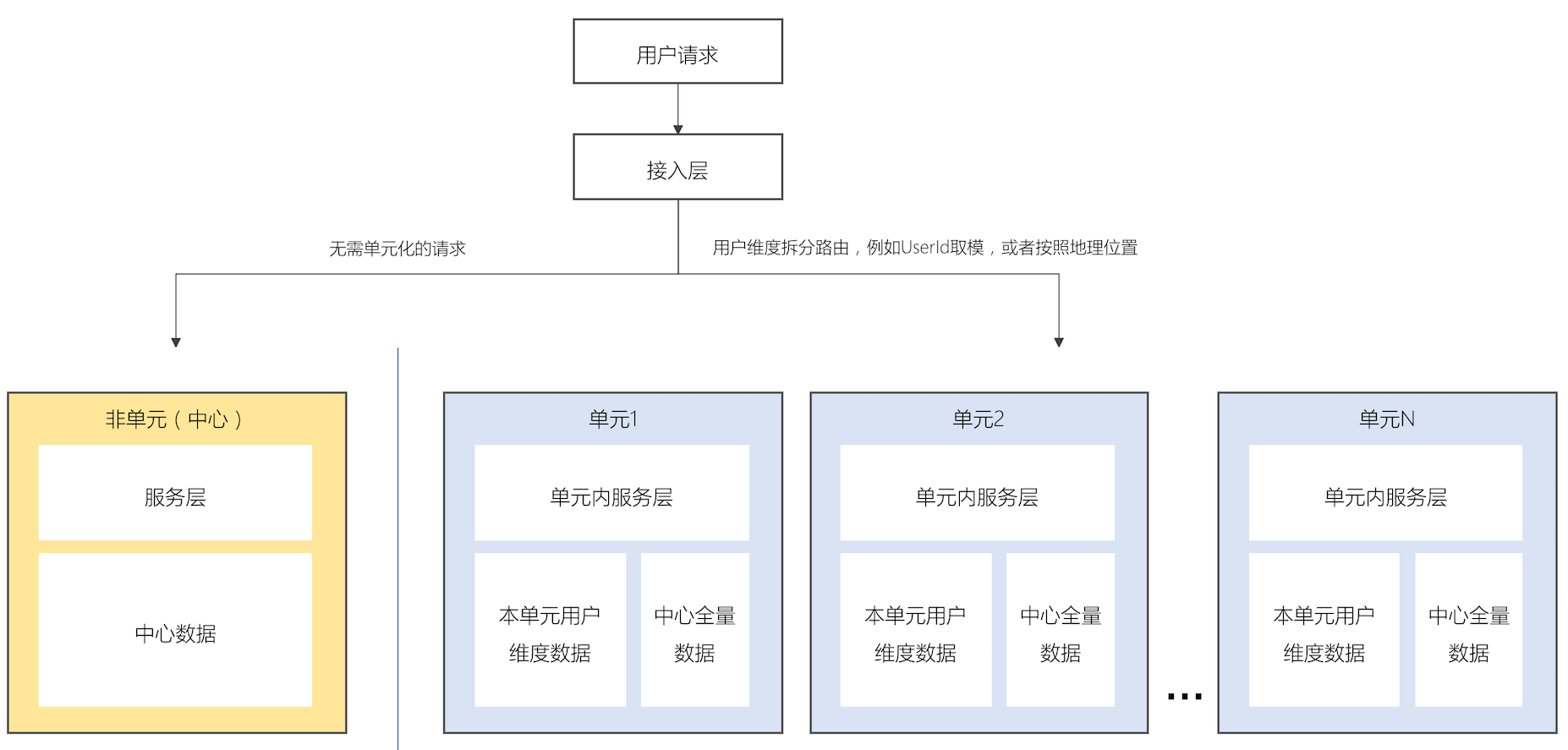
8. 单元化
异地多活的弊端显而易见就在跨地域延迟上,解决的办法可以”单元化“(unit),这个概念是阿里提出来的,也就说让请求收敛到同一区域内完成,单元高内聚,不做跨区域访问,即“单元封闭”。然而不是所有服务都是单元化的,一些长尾和小流量应用可以只做”中心化“架构,仍然靠冷热备做容灾。
单元封闭的策略可以按照某个业务维度拆分用户,例如阿里买家是按照userId取模划分单元,饿了么按照user所处的地域划分。
如下图所示按用户分流两个地域,单元化的架构如下。这样的架构里面存储也是单元化的,只承载本单元的请求,和路由的策略保持一致。
9. 存储层的高可用与数据一致性
本文不谈高端存储,只谈基于commodity hardware之上的存储,例如互联网公司常用的MySQL或者分布式数据库。
MySQL在本区域或者跨区域的高可用可通过主从复制(replication)+多副本(replica)实现,一个实例做standby,主故障即可切换,其他从可以做本区域或者跨区域的复制,仅做只读,扩展读能力。
然而MySQL可以做到RPO=0吗?数据强一致吗?
如果采用异步复制,必然有损,切换过程中主库未来得及同步过去的数据会丢失,RPO>0,如果从提升为主继续服务自然就不一致了,此时还有”脑裂“这种双主可能性的存在,如果停止服务,则可用性又受到影响,一般服务也不会牺牲可用性。
如果采用半同步复制semi-sync,即主库在返回客户端成功之前,需要保证从库ACK接受到binlog,对于是否影响幻读又可以设置AFTER_SYNC还是AFTER_COMMIT模式,注意开启semi-sync会影响写性能。
那么开启semi-sync,就能保证RPO=0吗?也不一定,一般数据库采用InnoDB引擎,MySQL在Server层面采用2PC进行提交,在事务的Prepare阶段Redo log写完日志,事务不是commit状态,需要走到Server层面,Binlog写成功,才进行解锁、清理Undo log的commit工作,再返回客户端。
写Redo log和Binlog都有相应的参数控制。
innodb_flush_log_at_trx_commit控制InnoDB Redo log的刷盘的频率控制。
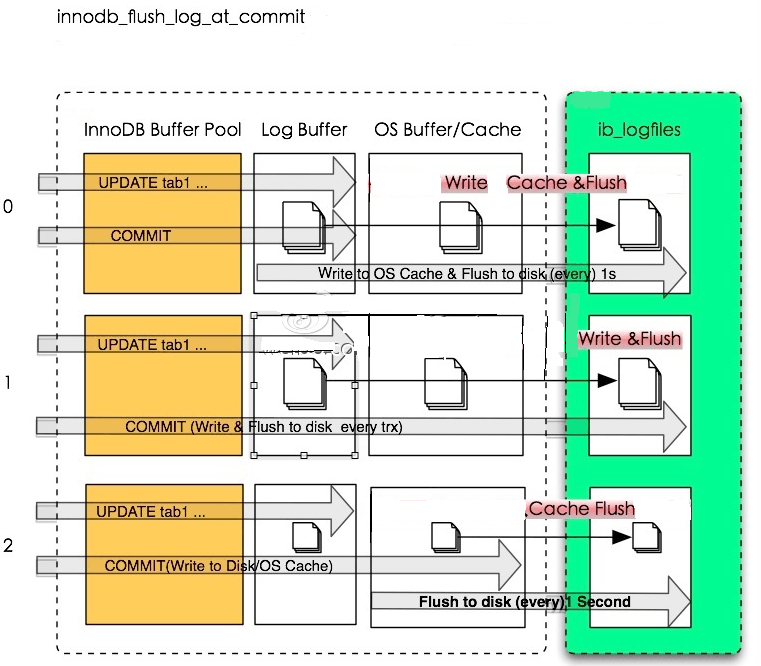
图片来源点此
innodb_flush_method控制InnoDB相关文件的刷盘走什么模式,经过Page Cache还是Direct IO。
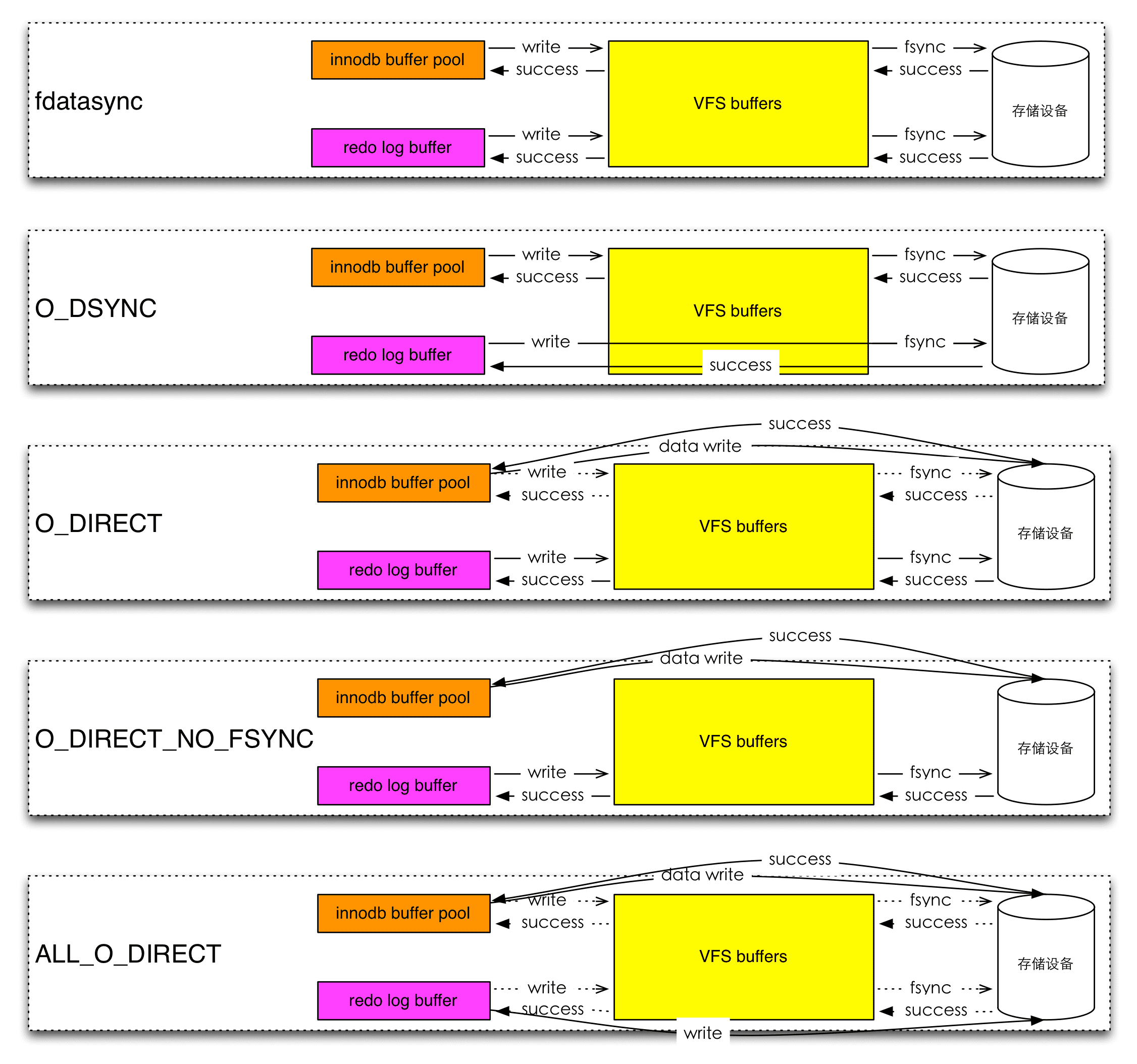
图片来源点此
当MySQL进程crash或者操作系统挂掉,binlog是否传输到从库,相应的文件有没有落盘,都会造成客户端、主库、从库的数据不一致。
举个例子,假设在Prepared阶段,MySQL或者操作系统crash,如果Redo log或者Binlog任意一方丢了,那么客户端的确会感知失败了,主库再次恢复会rollback,如果binlog同步到了从库就生效了,从而出现主从不一致。
数据一致性的范畴应该限定于数据库实例,不参考客户端的态度。MySQL的主从,再加上刷盘,是不能保证数据强一致的。但是从另外一个层面理解,如果采用semi-sync+强制刷盘的策略,可以做到不丢数据,但是实例之间的数据一致性是无法保证的。
但是为了满足可用性要求,减少数据不一致,有一些策略可以优化,例如,
1)采用保护模式,如果主库挂掉,在恢复后避免直接写,可以尽可能的把diff apply到从库上,如果没有冲突,则安全;如果有冲突采用业务对账手段订正数据。
2)对于切换期间正在写入的用户,可以做一些降级,开启禁写,避免其再写新主库,导致数据不一致,可用性达标不需要满足100%的用户,真发生灾难了,原则上满足绝大部分用户才是关键。
10. 跨区域存储复制
一般互联网公司都看重可用性,面对跨地域的高延迟和网络抖动,binlog同步不是个好办法,那么存储层面的复制可抽象为利用通用的DRC(Data Replication Center)中间件解决,阿里云的解决方案即是DTS(Data Transmission Service)。这类中间件可以提供稳定的秒级复制,保证事务一致性的实时DB同步,其原理一般是伪装为数据库的binlog,异步的将数据进行复制远程传输,中间件本身可以做持久化,便于实现一次订阅,多点分发的特性。这种方式注重AP,牺牲了异地的一致性。
在”单元化“异地多活的架构里,DTS可以承担单元和中心间的数据复制功能,中心数据广播到各个单元,单元之间也做数据同步,例如饿了么的商家数据广播到各个单元,这样请求可以做”单元封闭“;单元间的同步做双向复制,又支持了区域故障时候的机房切换。
11. 分布式数据库
现在越来越多的数据库采用分布式数据库系统,例如Google的Spanner,阿里巴巴的PolarDB,Oceanbase,开源的Tidb和CockroachDB等,他们可实现存储层的数据一致性,其依赖Paxos或者Raft协议。把存储近似看做一个状态机,对数据每次修改都可以看做一次增量日志,事务的实现,可以在存储上套一层Paxos或者Raft协议。例如,三个节点的集群,Raft的Leader负责写,Leader的事务日志同步到follower,超过多数派(majority quorum)落盘后,再commit。这种架构对于写入的延迟明显高了,但是这种小幅的牺牲却可以保证数据强一致。而吞吐可以靠拆分解决,可以存在很多的Raft Group,数据按照Range进行分区,还可以做二级分区,这种的sharding效果等同于分库分表,而扩展性、灵活性和容灾能力更好。只要有半数以上的节点正常就能保证分布式数据库正常工作,当Leader节点故障时发起Leader election自行恢复,无需人工switch over或者failover。
在阿里云上的”金融级“RDS,其原理也是在MySQL内核上套用一个Raft状态机控制事务,保证了数据的一致性,由于分布式数据库的依赖Paxos或者Raft,所以延迟更是问题,一般部署在同地域,例如”金融级“RDS要求部署在同一个区域,依赖DTS做异地复制。
分布式数据库单Group至少3个节点,更加可靠的方案可以采用5个节点,3地3机房5副本,参考蚂蚁金服Oceanbase的”五地三中心“架构,Zone1和Zone2同城双机房,Zone3和Zone4同城双机房,一个距离稍远的可以设计为仅做日志副本,节省空间,同时减少延迟带来的吞吐下降,可做到RPO=0,RTO几十秒,强一致,可抵御个别硬件故障、机房级灾难和区域级灾难。

12. 总结
本文先介绍了应用系统的构成和部署方式,然后从演进的角度分析单机房、同城多活、异地灾备、异地多活、单元化的架构,最后针对存储的多活,特别是数据库,从微观角度分析了存储层的高可用与数据一致性,对于异地的复制采用类DRC的中间件,最后介绍了强一致和高可用的分布式数据库。其中各个点都是浅尝辄止,旨在让读者有一个宏观上的概念和对构建异地多活的应用系统有个体系化的认识,一些细节可以按图索骥的深入展开,这也是作者在不断学习努力的方向,愿共勉。
转载时请注明转自neoremind.com。
整理得非常好,学习了!
感谢支持!邮箱很霸气~ github上已follow。