
Nesto – Hulu用户分析平台的OLAP引擎
本文主要介绍Hulu用户分析平台使用的OLAP引擎——Nesto(Nested Store),是一个提供近实时数据导入,嵌套结构、TB级数据量、秒级查询延迟的分布式OLAP解决方案,包括一个交互式查询引擎和数据处理基础设施。
1. 项目背景
2. 数据平台pipeline
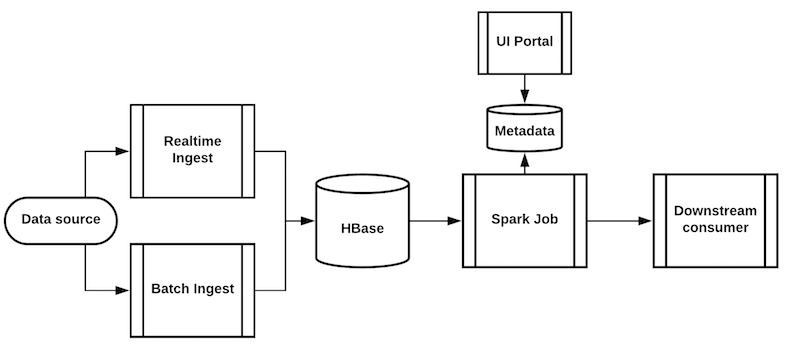
{
"uid": 100,
"raw_attributes": {
"email": {"value": "jack@hulu.com"},
"gender": {"value": "m"},
"signup_date": {"value": 1507359323},
"age": {"value": 49}
},
"behaviors": {
"watch": [
{
"cid": 9800,
"duc": "Living Room",
"dlc": "CONSOLE",
"seventid": 800,
"genre": ["Documentaries"],
"video_type": "feature_film",
"timestamp": 1273774176
},
{
"cid": 9801,
"duc": "Living Room",
"dlc": "CONSOLE",
"sid": 801,
"genre": ["Animation and Cartoons", "Family","Kids"],
"video_type": "feature_film",
"timestamp": 1373774176
},
{
"cid": 9802,
"duc": "Computer",
"dlc": "EMBED",
"sid": 802,
"genre": ["News and Information"],
"video_type": "clip",
"timestamp": 1473774176
}
]
}
} |
SELECT reg.raw_attributes.username, reg.raw_attributes.email FROM RegUsers AS reg WHERE ARRAY_COUNT( (SELECT w.cid FROM reg.behaviors AS b UNNEST b.watch AS w WHERE w.cid = 9800 AND w.ts >= '2018-01-01 00:00:00' AND w.ts < '2018-02-01 00:00:00') ) > 5 AND reg.raw_attributes.reg_at >= '2018-01-01 00:00:00' AND reg.raw_attributes.reg_at < '2018-02-01 00:00:00'; |
3. 数据规模
目前用户数据规模如下,
1、HBase 1500 Regions, 占HDFS 20T (一副本、LZO)
2、300+列,其中有50多是嵌套的结构,例如观看行为。
3、1亿+用户数据。
4、历史全量近1000亿观看行为,最近一年近300亿次。
4. Nesto的诞生
为了满足OLAP的需求,包括
1、支持filter, projection和aggregation和自定义UDF。
2、Ad-hoc查询, 普通列响应时间秒级,嵌套列小于百s。
3、数据从进入OLAP到能够被查询到,延迟要在小时级别。
我们对比了如下开源方案,
1、ROLAP
类似SparkSQL、Presto、Impala等,它们都必须把数据抽象为关系型的表,可以使用表达丰富的SQL,不存在数据冗余,在实际运行期间往往会经过SQL词法解析、语法解析、逻辑执行计划生成和优化,再到物理执行计划的生成和优化,会存在数据shuffle、join。这与现有的用户分析平台已存数据模型——大宽表,不一致,需要经过ETL做数据转换。另外我们的另一个目标支持近实时的数据导入,而这些方案的OLAP目前都不支持。
2、MOLAP
类似Druid、Kylin、百度Palo等,他们都支持多维查询,通过预聚合的方式来提升查询性能,但是需要抽象出维度列、指标列,甚至某个维度的分区等。同样数据模型和大宽表不一致。另外,用户分析平台往往涉及一个用户所有行为数据,查询请求往往就是要查询若干月,甚至若干年之前的,涉及大量fact数据的全表scan,这也不能很好的match这种物化视图或者上卷表的模式。
5. Nesto的基础
Nesto的实现依赖于一些已有的技术和理论。
1、存储模型。采用嵌套模型,非关系型。
2、存储格式。列式存储,对于OLAP,可以跳过不符合条件的数据,降低IO数据量,加大磁盘吞吐。通过压缩、编码可以降低磁盘存储空间。只读取需要的列,甚至可以支持向量运算,能够获取更好的扫描性能。Nesto采用Parquet作为存储格式,是Google Dremel的开源实现。Parquet对嵌套数据结构实现了打平和重构算法,实现了按行分割(形成row group),按列存储(由多个page组成),对列数据引入更具针对性的编码和压缩方案,来降低存储代价,提升IO和计算性能。
3、MPP架构。大规模并行处理架构,可以支持查询的横向扩展,为海量数据查询提供高性能解决方案,实际上Nesto借鉴了Presto。一个Parquet文件是splitable的,因此利用DAC分治的思想,把大问题划分为小问题,分布式并行解决。
4、RPC选型。分布式系统的RPC通信是基础,Presto大量采用RESTFul API解决,而Nesto选择使用Thrift进行封装解决,提供基于NIO全双工、非阻塞I/O的通信模型,通过Reactor模式实现线程池和串行无锁化来实现服务端API的暴露。
5、分布式配置。Nesto中的表结构存储在分布式配置系统中,可做到热部署更新。
6、高可用保证。使用YARN管理实例,保证高可用和资源的合理分配。使用Zookeeper做集群节点变更的通知与分发。
7、海量数据近实时查询支持。借鉴Google MESA的思想,关于MESA的模型,请参考这篇文章了解《浅谈从Google Mesa到百度PALO》。
8、其他技术点。使用MySQL存储已完成任务情况,使用web技术构建管理Portal。使用Hadoop基础设施,包括HDFS存储数据。
9、实现语言。Java。
6. Nesto的存储模型
逻辑上,可以看做一张嵌套的大平表(flat table),数据按照行存储,每一行的结构都是嵌套的。和第二章提到的HBase的模型逻辑上是一致的。
物理上,采用开源列式存储方案,Nesto选择Parquet,它独立于计算框架,按照Google Dremel提到的方案做按行切割,按列编码压缩。一张表对应1到N个Parquet文件。
下图是Parquet官网的物理存储图。每个Parquet文件都是包含若干row group,这是做MPP的基本分割单元,一个MPP的sub-task可以对应K个row group,一个row group包含了若干用户的全部信息,按照schema定义的列,进行列式存储,每列包含若干个page,每个page是最小的编码压缩单元。每个列都可以采用自由的编码方式,例如run length encoding、dict encoding、bit packed encoding,delta encoding等等,或者他们的组合。
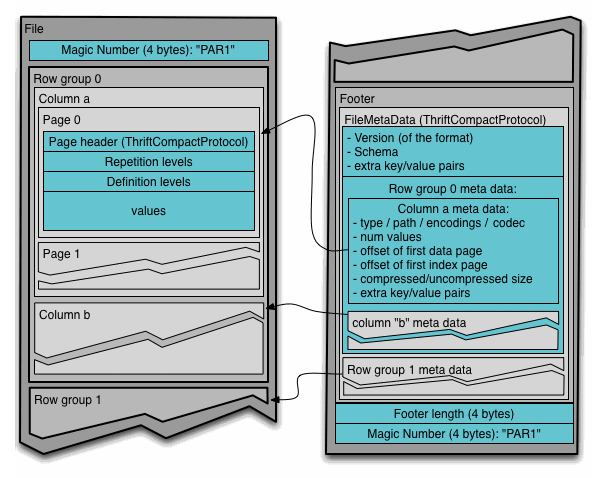
用于MPP架构的存在,通常会多增加副本数,来支持读负载均衡和本地化locality查询。
表结构元数据不用DML描述,而是使用Parquet提供的proto schema方式,目前通过分布式配置中心管理,通过管理控制台新增表和修改表。例如,在配置中心表RegUsersAttributes的schema描述如下。
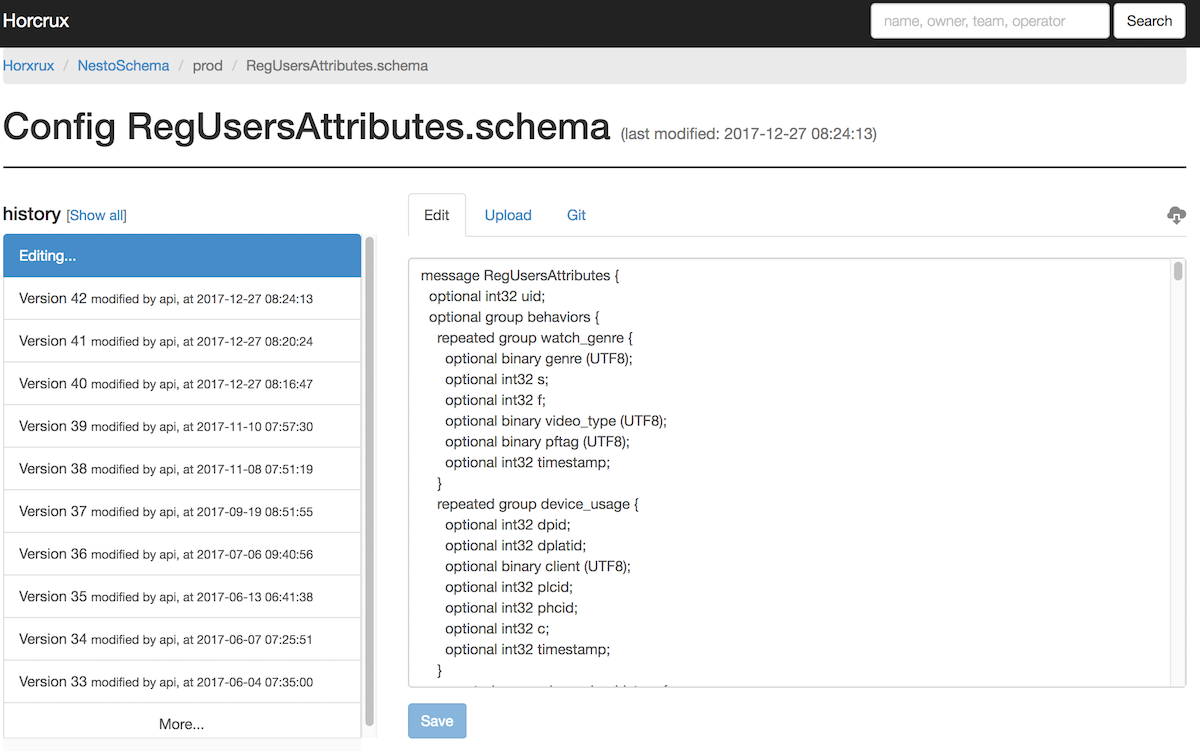
7. Nesto整体架构
Nesto分为查询引擎和数据处理基础设施两大部分。
查询引擎的架构如下。
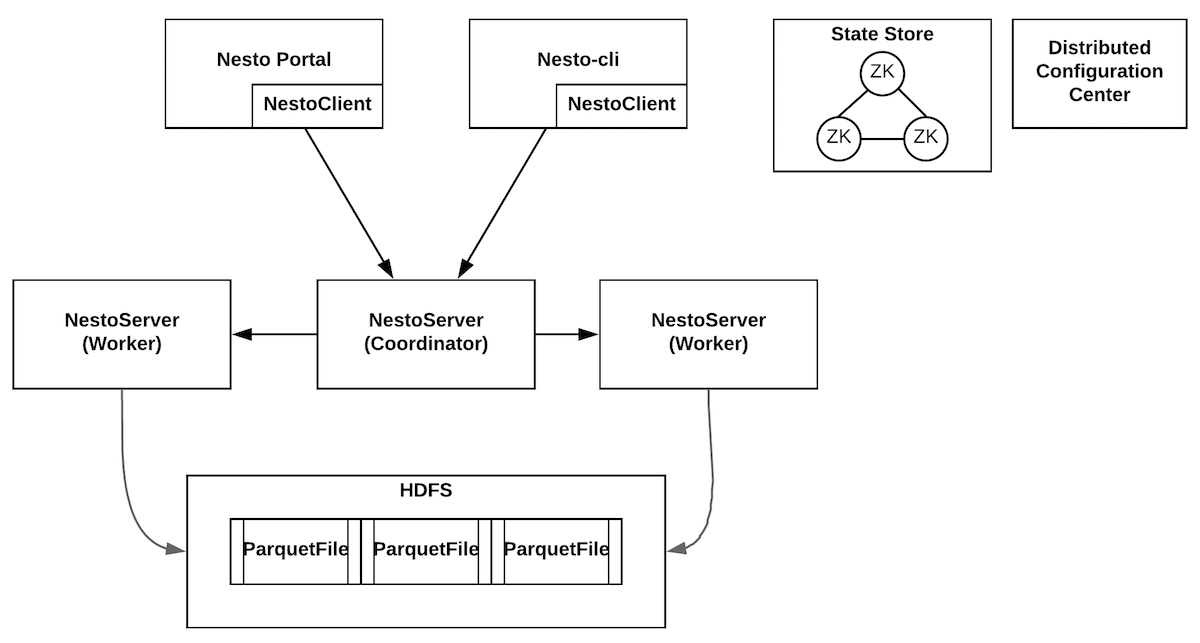
Nesto-portal。客户端,用于提供基于web的查询请求输入和下载结果。
Nesto-cli。客户端,提供命令行交互式的查询。
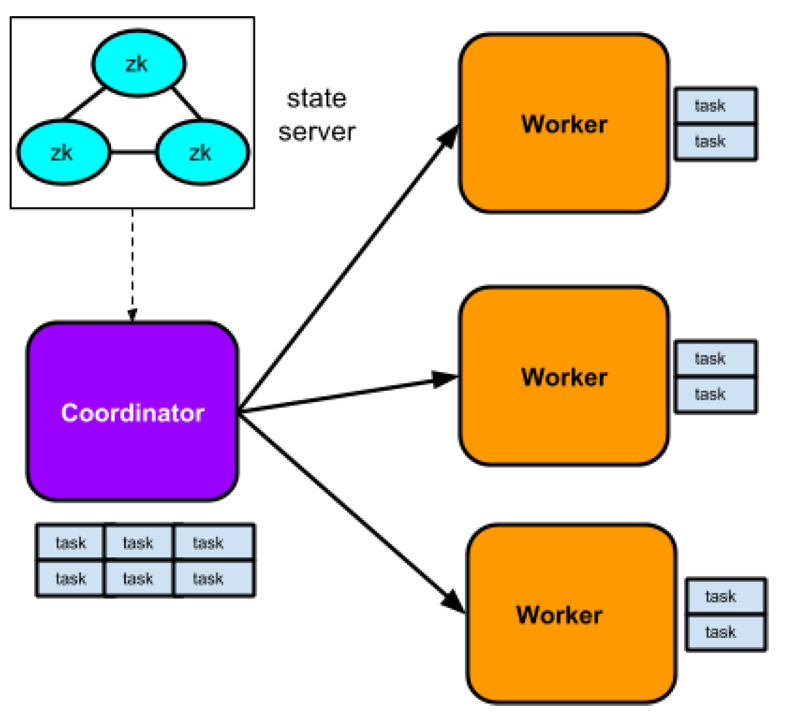
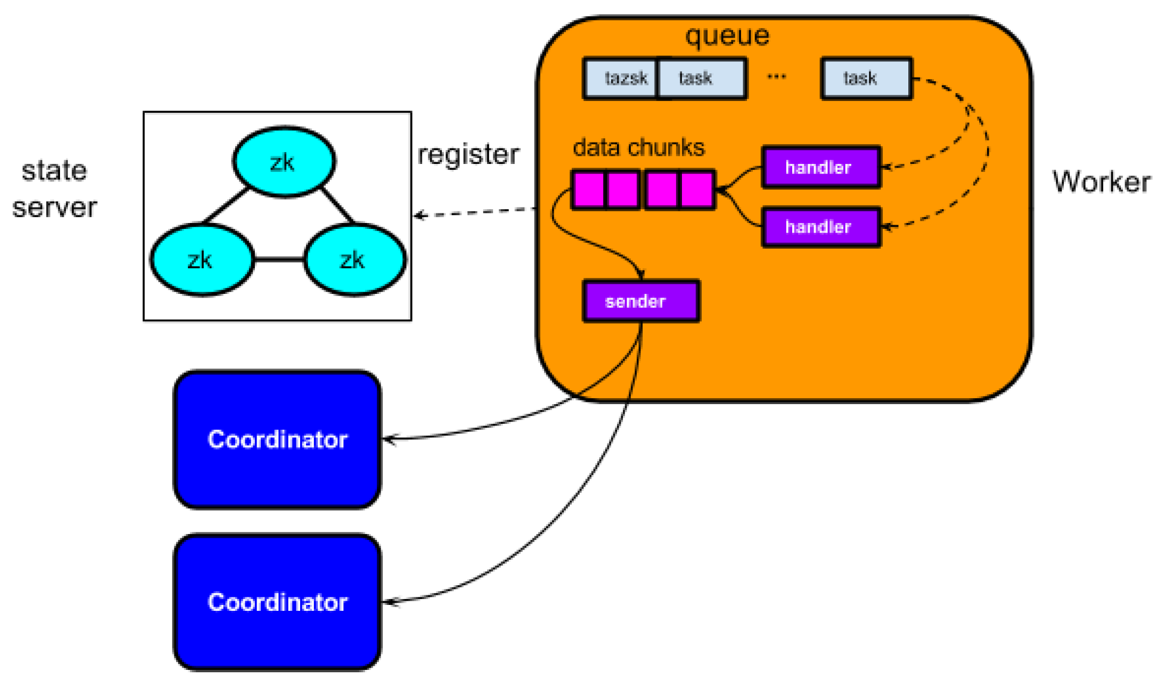
State store。使用zookeeper来做集群管理,进而实现高可用的分布式系统,任何节点都可以知道整个Nesto的拓扑结构。
Nesto server。非中心化的设计思想,类似Presto,任意节点分为两种角色,包括coordinator和worker,一般来说都是少数的coordinator加上大量的worker的拓扑。每一个部署节点都是一个Nesto server,只不过角色有区分。目前nesto-server均部署在YARN上,做常驻进程,YARN做高可用保障和资源分配管理。
Coordinator。是某一个查询的管理节点,负责接收客户端的请求,解析请求,由于使用大宽表的数据结构,加上复用predicate lib,因此做完词法分析、语法分析,生成AST后,查询计划的生成很简单,把filter的逻辑全部下推到底层的worker去执行即可,只需要做table的split就可以生成sub-tasks,这些sub-tasks就是物理执行计划的体现,所以不存在stage或者fragement等类似Presto、Impala的概念。Coordinator通过State store感知集群的拓扑,同时和每个worker都保持了一个心跳,worker通过心跳信息上报自己的状态,coordinator可以进一步了解worker的负载和健康状态。Coordinator通过一定的调度算法,把sub-tasks分发给worker去执行,等待worker的结果汇总过来,如果需要再做一些aggregation和merge的工作。最终,流式的传输结果给客户端展现或者下载。
Worker。接收coordinator分发的若干sub-tasks,放到线程池中执行(线程池就是槽位slot),通过Parquet提供的API,逐一读取一行的数据,利用predicate lib进行filter,通过一个异步的生产者消费模型,批量处理数据,然后分批序列化后,按照data chunk的方式,源源不断的发送回coordinator。另外,worker会做一些优化工作,除了天然的filter pushdown,还包括pre-aggregation,limit pushdown等等。
数据处理基础设施请参考第9章节。
8. Nesto的查询引擎
下面针对一个典型的查询执行过程,进一步展开描述各个组件的工作流程。
8.1 State store
8.2 Nesto-server之Coordinator
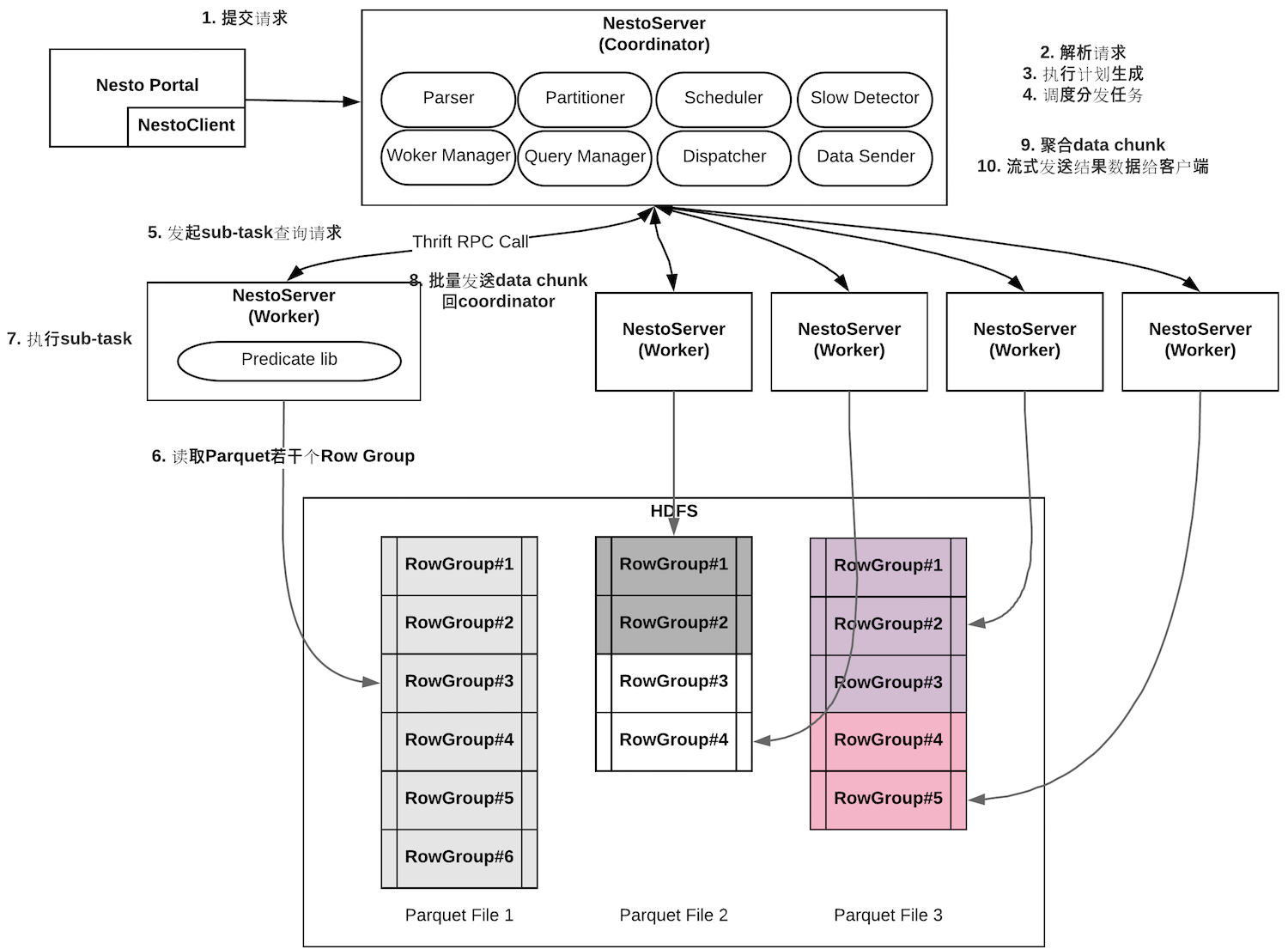
API
解析请求
执行计划生成
调度分发任务
查询执行
失败处理
8.3 Nesto-server之worker
8.4 Portal & Cli
./nesto-cli -mode i -schema RegUsersAttributes -table_path hdfs://nesto/RegUsersAttributes/sl2-prod-100 No JAVA command specified AND try TO USE $JAVA_HOME OR just "java" instead. _ _ _ _ _ | \ | | ___ ___| |_ ___ ___| (_) | \| |/ _ \/ __| __/ _ \ _____ / __| | | | |\ | __/\__ \ || (_) |_____| (__| | | |_| \_|\___||___/\__\___/ \___|_|_| Welcome TO Nesto-cli. http://test.com/STATUS will be used AS Nesto portal Starting... Coordinator test.hulu.com:58807 will be used TO serve calls TYPE 'help', TYPE 'bye' TO quit > SELECT reg.raw_attributes.username, reg.raw_attributes.email > FROM RegUsers AS reg > WHERE > COUNT( > (SELECT w.cid > FROM reg.behaviors AS b > UNNEST b.watch AS w > WHERE w.cid = 100 > AND w.ts >= '2018-01-01 00:00:00' AND w.ts < '2018-02-01 00:00:00') > ) > 20 > AND > reg.raw_attributes.reg_at >= '2018-01-01 00:00:00' AND reg.raw_attributes.reg_at < '2018-02-01 00:00:00'; Querying......... IF nesto.query.quite SET TO FALSE, visit http://test.com:8090/query.jsp?queryid=query_aaa_60066_106 FOR more info. ........ ScannedCount: 109586, RowCount: 4 raw_attributes.username.value | raw_attributes.email.value ---------------------------------+------------------------------------- Jack | jack@abc.com Richard | richard@abc.com Christy | christy@abc.com Jeanette | jeanetteburel@abc.com Total records: 4 Query done. (costs 2 seconds) ``` |
8.5 部署
Nesto在部署上,默认采用YARN来管理,以进程常住的形式部署在YARN Node节点上,通过利用YARN的编程接口,开发Client、AppMaster等程序,就可以管理coordinator和worker常驻进程,做到高可用保障和合理的资源分配。
另外,Nesto也支持本地standalone和pseudo伪分布式部署模式,方便调试和测试。
9. Nesto的数据处理基础设施
前面介绍了Nesto的查询引擎,还包括一个数据处理基础设施。
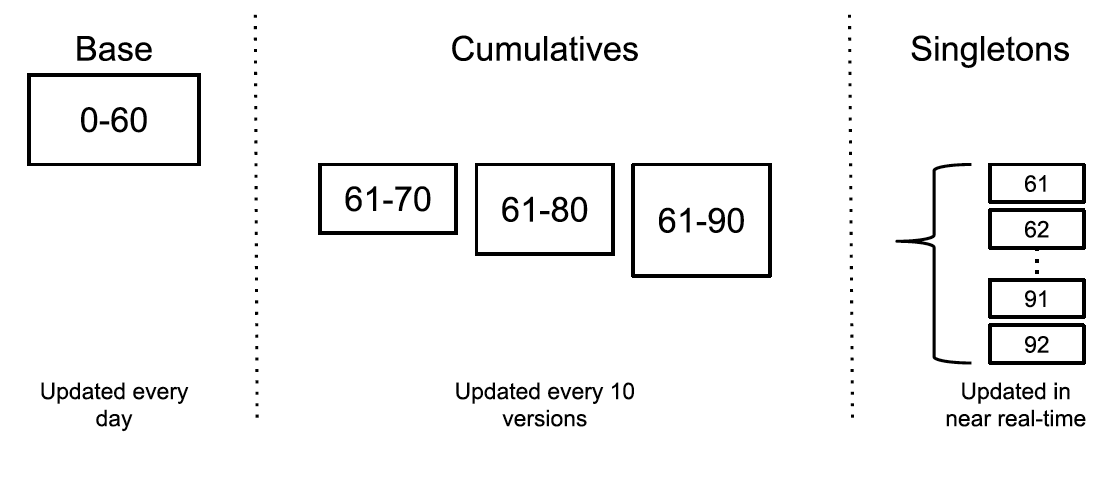
Nesto支持近实时数据导入,利用了Google MESA提供的数据模型,由Base、Cumulative delta和Singleton delta组成。如下图所示。
数据处理基础设施架构图如下。
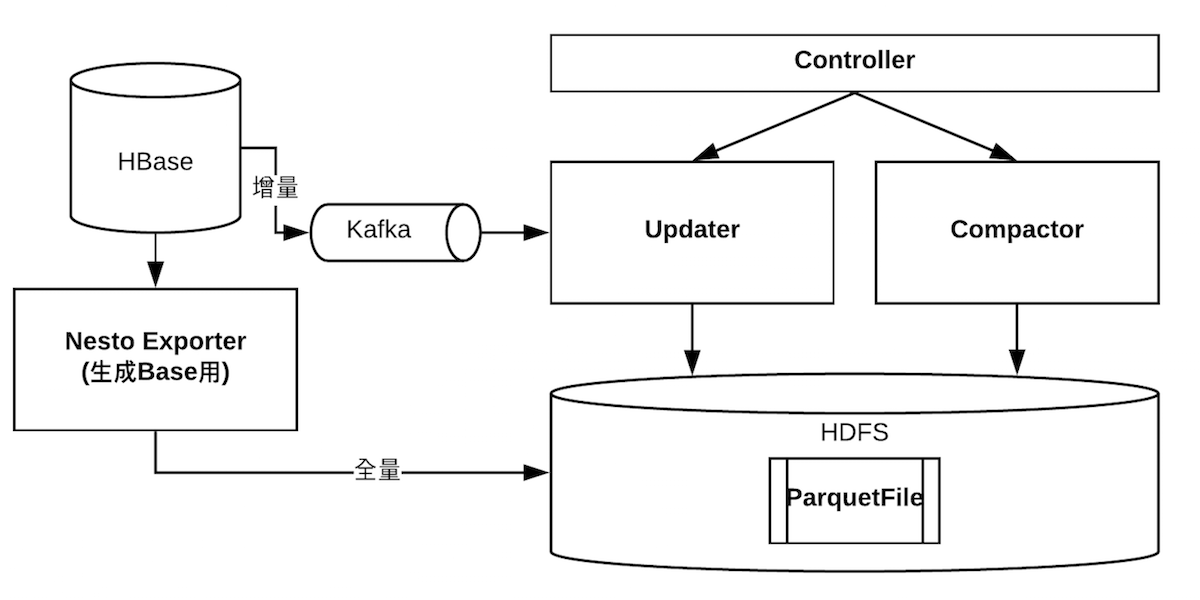
其中Base文件定期通过ETL任务导出,由于数据量大(历史全量数据,1000亿行watch行为,300多列),因此这是一个很重的任务,而每天变化的数据量又非常小,因此尽可能低频率的运行。在图中体现为exporter组件。
Delta文件的生成通过HBase coprocessor捕获,并且发布到Kafka中做存储,多分区,单分区内数据可保序,因此单个用户不会存在业务上的乱序影响。增量处理程序以小时级的频率生成delta。在图中体现为updater组件。
当过多的delta存在的时候,查询引擎会进行更多的随机I/O,不利用优化响应延迟,因此存在一个job以若干小时的频率合并delta为一个大的delta,叫做cumulative delta。在图中体现为compactor组件。
Updater和compactor会通过controller进行调度运行,他们都是无状态的,因此通过controller保存和注册生成的delta,每个delta都要一个version,查询引擎在做执行计划生成的时候,可以访问controller查询最优的query path。
在上面几个章节的查询引擎介绍里都简化了处理,没有考虑增量情况,便于读者理解。
这里要注意,在查询引擎中使用delta,就必须保证和base中的row group中的行都是match的,这里的任务都会按照某个业务主键,例如userid,来排序文件,这样在查询引擎内部就可以使用基于最小堆的多路归并排序来做数据的merge了。
10. 总结和未来计划
目前Nesto在Hulu内部承担着实时用户数据OLAP查询的需求,供PM、运营人员使用。目前线上仅需部署了60个nesto-server节点,最大表的Parquet文件大小在3-4T(单副本压缩后),对于简单列的查询,在秒级完成,对于包含watch行为的嵌套列,在百毫秒以内完成。
未来Nesto的增强点包括使用基于codegen技术的predicate lib(目前内部已完成借助spark sql catalyst的改造),最大化filter性能。冷热数据区分,智能表路由,避免粒度过粗的full scan。数据拖敏,更好的安全保障。通用化的平台,支持多租户的使用。更好的支持嵌套SQL查询。
目前Nesto由于绑定了内部的predicate lib,同时还利用了Hulu内部的很多基础实施,有些实现不是非常的通用,所以暂时还无法开源出来。
总结下,本文介绍了Hulu用户分析平台使用的OLAP引擎Nesto,它是一个提供近实时数据导入,嵌套结构、TB级数据量、秒级查询延迟的分布式OLAP解决方案,包括一个交互式查询引擎和数据处理基础设施。虽然Nesto是一个in-house的内部系统,但是本文还是最大化的展示了一些背后的架构、思想、实现细节,以及自研的tradeoff和原因,希望可以给读者一些OLAP方面的启发。现在的OLAP市场百花齐放,但是其思想和技术都是建立在已经成熟或者前人的基础上的,通过更好的理解和应用这些思想和技术,来满足组织和业务的需求,才是大家的目的,希望在OLAP领域与读者共勉一起学习和进步。
附录
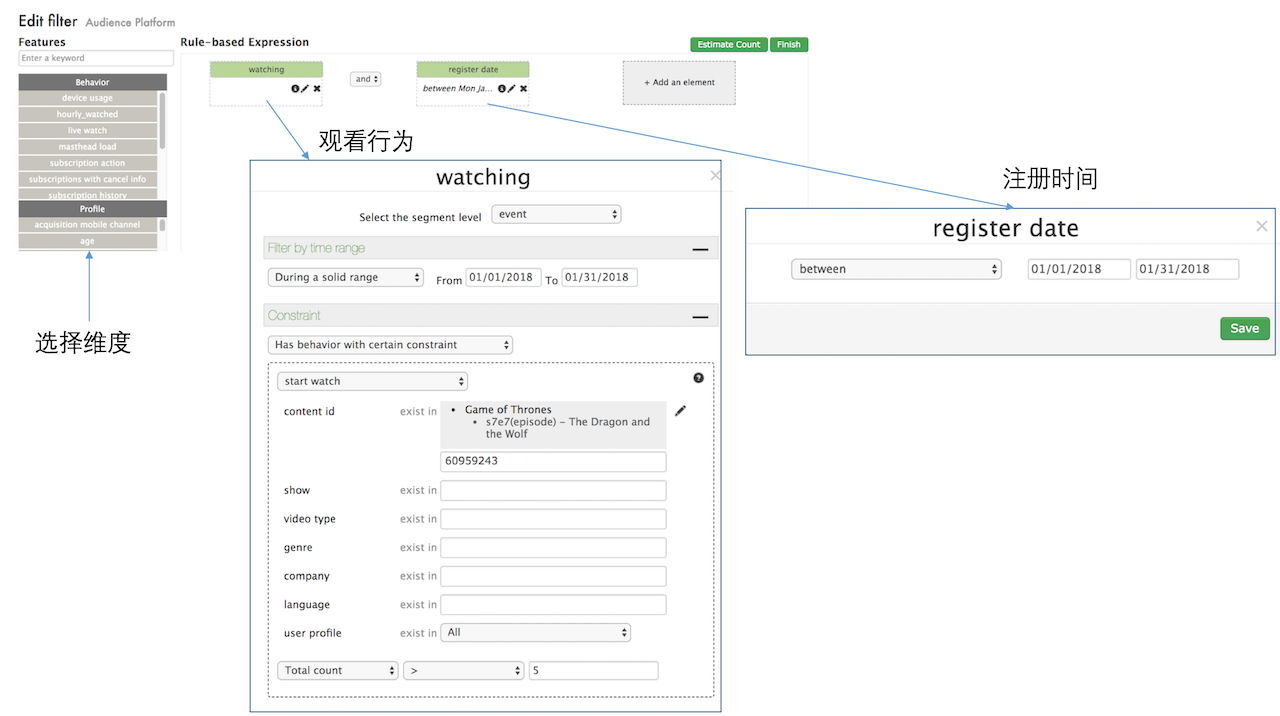
1、JSON DSL
导出2018年1月看过《冰与火之歌》第7季第7集(S7E7)超过5次的新注册用户,保存为csv,包括用户名、email两个域。
{
"expr":[
"and",
["greater_than",
[
"count_list",
[
"list_filter",
"cid",
["time_range_filter","in_range",1514764800,1517443199,["get_var","watch"]],
["get_function","exist_in"],
"9800"
],
"cid"
],
5
],
["in_range",["get_var","plus_signup_date"],1514764800,1517443199]
],
"results":["reg.raw_attributes.username", "reg.raw_attributes.email"]
} |
转载时请注明转自neoremind.com。
讲得很清晰,赞
很想知道schema在线变更是如何实现的
schema变更我是用推的模式,中心化保存proto desc,然后推送到查询节点,reload即可。
讲的很透彻 谢谢博主。
旭哥出品,必属精品。
谢谢捧场~